
Key Takeaways
The week before a regulatory audit, an operations team at a financial services company had to untangle compliance questions scattered across thousand-page PDFs. They pulled three consecutive all-nighters, shuttling between footnotes and appendices just to feed a retrieval system with clean snippets. The real cost was not overtime, it was the institutional knowledge trapped in static layouts. I wrote this piece so the next team can spend that week shipping features instead of screenshotting tables.
Meet Docling
Docling starts with a blunt truth: most enterprise data still lives inside formats that large language models cannot digest. PDFs, slide decks, and scanned contracts break naive OCR pipelines with multi-column flows, split tables, and embedded images. Docling was designed to bridge that gap. Built at IBM Research and released under the MIT license, it combines a CLI and Python library that runs entirely on a laptop. The first conversion can be as simple as five lines of code with DocumentConverter(), yet under the hood you inherit a pipeline that fuses a C++ PDF parser with layout AI.
The magic lives inside DoclingDocument, a Pydantic model that acts like an in-memory DOM. It stores every heading, paragraph, table, caption, and picture along with provenance such as page numbers, bounding boxes, and the content_layer flag that tells you whether an item belongs to the main body or the header and footer bands. Layout intelligence comes from DocLayNet, a vision model trained on annotated pages spanning patents, manuals, and financial reports, paired with TableFormer for cell-level structure. Docling avoids OCR unless it hits a scanned page, which keeps text fidelity high and dramatically reduces the latency compared with forcing an OCR pass across every page. When the pipeline finishes, you can export to Markdown, HTML, JSON, or DocTags without losing relationships between elements.
Architecture at a Glance
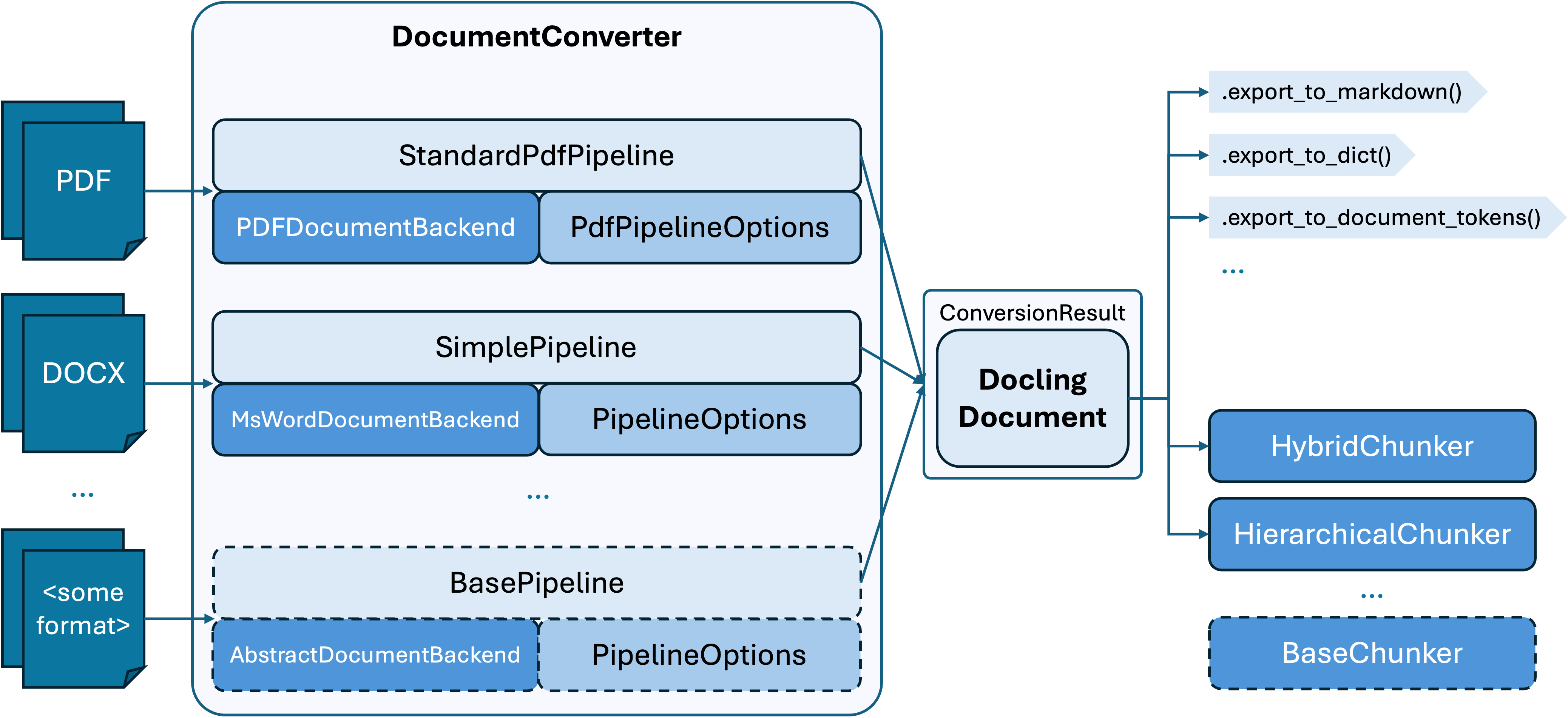
Docling’s architecture keeps the DocumentConverter at the center. Each format maps to a backend parser and a pipeline (StandardPdfPipeline for born-digital PDFs, SimplePipeline for Word files, and so on). Those defaults are only starting points: swapping pipelines or option bundles lets teams tune throughput, OCR budgets, or enrichment steps, while still landing on the same ConversionResult object that downstream chunkers or serializers expect.
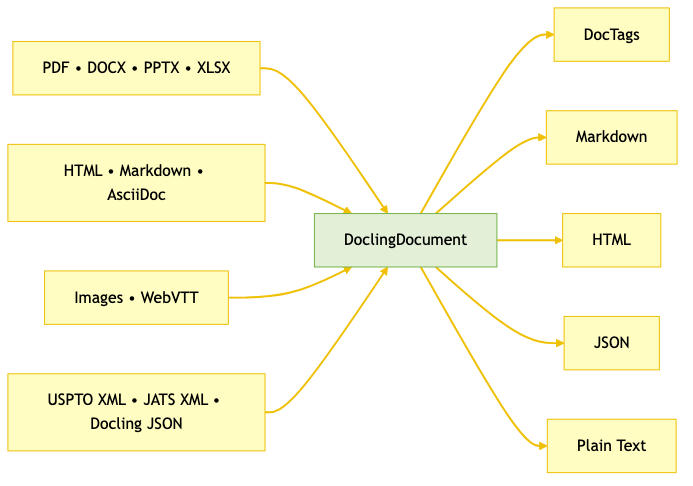
Docling meets you where your data lives: born-digital office bundles, web-native content, domain-specific XML, and scanned evidence. The same DoclingDocument exports to Markdown, HTML, JSON, plain text, or DocTags so your downstream workflows keep structure intact. When you need the exhaustive matrix, head to Docling’s supported formats.
DocTags, Docling’s Structural Language
DocTags is the universal markup IBM Research created for the broader Docling ecosystem. The Granite-Docling AI model emits it natively, and the standard DocumentConverter and CLI pipelines can export any DoclingDocument to the same vocabulary. Each tag isolates the content, bounding box, page index, and structural role of an element, so captions never drift from their figures and footnotes stay paired with the right paragraph. Because the vocabulary is purpose-built for layout AI, DocTags lets neural and rule-driven pipelines reason about multi-column flows, math, or forms without bloating token counts.
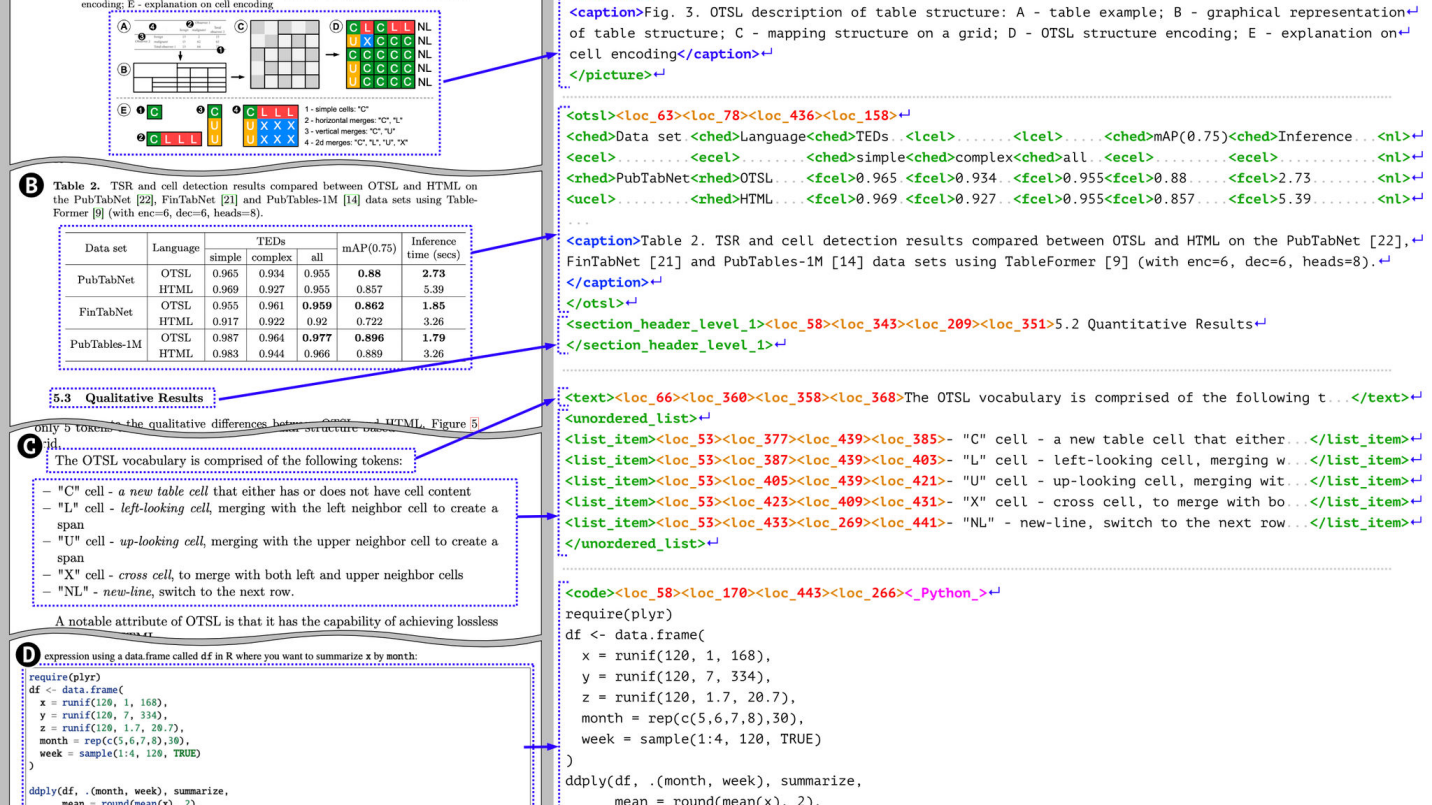
Inside the DoclingDocument
DoclingDocument is the typed backbone that makes downstream work predictable. The object is a Pydantic model that exposes the entire hierarchy: pages with their dimensions, body items grouped into headings, paragraphs, tables, and pictures, and header or footer regions flagged via each item’s content_layer. Every node carries provenance via DocItem.prov so you can trace back to page numbers and bounding boxes.
from docling.document_converter import DocumentConverter
result = DocumentConverter().convert("reports/sustainability.pdf")
doc = result.document # DoclingDocument
Treat the DoclingDocument as a document DOM: traverse it to build custom chunkers, attach enrichments, redact PII by location, or generate breadcrumbs for RAG responses without re-running the converter.
Docling Pipelines
Docling gives you more than one path from PDF to structure. SimplePipeline for born-digital layouts when you want the classic Docling stack. The VLM pipeline upgrades that flow with Granite-Docling or other multimodal LLM, whether you host it locally or via a remote OpenAI-compatible endpoint. ASR keeps pace with meetings and briefings by running Whisper-based transcription. The table below summarizes when each option shines.
| Pipeline | Use When | Why It Works |
|---|---|---|
SimplePipeline | Born-digital PDFs or images where classical layout analysis, OCR, and enrichments suffice | Runs Docling’s default CV stack (DocLayNet, TableFormer, optional OCR/enrichments) for predictable throughput and fully offline operation |
VLM | Visual-heavy PDFs, scans, or slides that benefit from multimodal reasoning | Lets Granite-Docling, SmolVLM, or another multimodal model read pages holistically for Markdown/DocTags output with richer figure and caption understanding |
ASR | Audio or video sources that need transcripts | Wraps Whisper-based conversion so spoken content lands beside slide decks and reports inside the same DoclingDocument |
Activate the Ecosystem

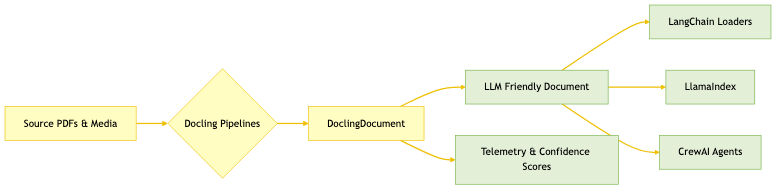
Once a document becomes a DoclingDocument, you can route it to the frameworks your team already trusts. LangChain’s DoclingLoader can either export consolidated Markdown documents or emit chunked outputs derived from Docling’s structure, so you choose between readability and fine-grained grounding. LlamaIndex’s Docling Reader serializes the full data model to JSON when you need lossless provenance, yet it can also down-convert to Markdown for simpler pipelines, while the companion Node Parser understands the richer format when you keep it. CrewAI treats Docling as the ingestion step for multi-agent workflows, and enterprise platforms like RHEL AI, Cloudera, and watsonx already embed Docling in their pipelines, which shortens the path from pilot to production.
Closing
The compliance team that once slept under fluorescent lights can now turn the same audit binder into a structured asset before lunch. DoclingDocument gave us the blueprint for keeping provenance, the pipelines showed how to match the right layout intelligence to every format, and the ecosystem integrations stitched that structure into enterprise stacks without extra glue code.
Keep the flywheel spinning: instrument your conversions with confidence scores so reviewers know where to intervene, swap in the VLM pipeline for visual-heavy decks, and lean on DocTags when you need provenance-aware chunking.