
Key Takeaways
Consider a common scenario: a team routes an internal LLM into a production support queue. The dashboards light up. The model invents a new status enum "almost_shipped", and downstream analytics choke on the unexpected string. Customers wait, on‑call engineers scramble, and the incident review surfaces the same root cause every time: the system trusted an unstructured response.
Pydantic is the contract that restores trust. It helps teams rescue flaky agents, tame tool‑calling chaos, and capture the breadcrumbs needed for responsible experimentation. This post distills practical patterns for anyone wrangling large language models into real products. We’ll move section by section, layering relatable scenarios, technical detail, and checklists you can apply today, so "almost_shipped" never reaches production.
When Friendly LLMs Break Production
Every LLM integration begins with optimism. You design a form so customers can report missing parts, pass their input to a model, and expect a tidy JSON response you can pump into ticketing workflows. Then reality bites: the model adds pleasantries before the JSON, forgets a closing brace, or improvises field names. Without guardrails, a single malformed field can ripple through billing, analytics, and customer care.
Pydantic gives you the leverage to enforce structural integrity even when the model improvises. Here's a minimal CustomerQuery schema used throughout this post:
from typing import List, Literal, Optional
from pydantic import BaseModel, EmailStr, Field
class CustomerQuery(BaseModel):
name: str
email: EmailStr
query: str = Field(..., max_length=2_000)
priority: Literal["low", "medium", "high"]
# Choose one of: refund_request | information_request | other
category: Literal["refund_request", "information_request", "other"]
is_complaint: bool
tags: List[str] = Field(default_factory=list)
order_id: Optional[str] = Field(
default=None,
description="Internal order identifier if present in the query.",
)
Feed the model output into CustomerQuery.model_validate_json(...) and you either receive a fully typed object or a precise ValidationError describing where the response went off the rails. Instead of praying for perfect prompts, you enforce a contract.
- Why it matters: Downstream systems receive typed fields, not creative guesses. When a field fails validation, you can halt execution before a bad enum pollutes your dashboards.
- Story payoff: The
"almost_shipped"incident never repeats because the schema refuses to accept values outside the known set. - Action item: Use these models to validate inputs to and outputs from LLM calls to ensure data integrity.
Teaching Data to Speak in Full Sentences
If Section 1 is about setting stakes, Section 2 is about giving models the vocabulary to succeed. LLMs thrive when you show, not tell. Instead of vague instructions such as “return JSON with user info,” you hand the model the exact schema it must follow.
# Step 1: Teach the model the schema it must follow
schema_hint = CustomerQuery.model_json_schema()
prompt = f"""
Analyze the following user query and respond with JSON that conforms
to this schema:
{schema_hint}
User query:
{user_input}
""".strip()
# Step 2: Let the model respond, then validate aggressively
raw = llm.invoke(prompt)
query = CustomerQuery.model_validate_json(raw)
Inside model_json_schema() lives a contract the rest of your infrastructure can rely on. The LLM sees concrete field names, descriptions, enum options, and constraints like maxLength. When validation fails, you respond with the error message, giving the model a coaching cue:
from pydantic import ValidationError
def repair(raw_response: str, error: str, retries: int = 3) -> CustomerQuery:
for attempt in range(retries):
try:
return CustomerQuery.model_validate_json(raw_response)
except ValidationError as exc:
error = exc.json()
raw_response = llm.invoke(
f"""The previous response failed validation with this error:
{error}
Regenerate a corrected JSON object that satisfies the schema."""
)
raise RuntimeError("Model failed after retries")
The result is a loop where validation errors become teaching moments. Like a senior engineer guiding a new teammate, you give the model concrete feedback and expect improvement. Over time, those retry prompts shape better behavior without mysterious prompt hacks.
Tip: when you need to reject coercion (e.g., avoid turning "5" into 5 implicitly), lean on strict types at the field level.
from pydantic import BaseModel, StrictStr
class UserInput(BaseModel):
quantity: int # allows coercion from "5" by default
sku: StrictStr # refuses coercion; must be a real string
Turning Validation Errors into Coaching Cues
Manual validation loops are a rite of passage. They force you to confront every assumption about the data shape you expect. Here's a small helper that wraps validation into a reusable function:
from typing import Tuple, Union
from pydantic import ValidationError
def validate_customer_query(payload: str) -> Tuple[Union[CustomerQuery, None], str]:
try:
return CustomerQuery.model_validate_json(payload), ""
except ValidationError as exc:
return None, exc.json()
By returning a tuple (validated, error_message), you avoid stack traces that confuse prompt engineers and product managers. Instead, you log the message, feed it back to the model, or alert the team if the failure repeats.
This is where storytelling meets instrumentation. Imagine a customer named Aisha reporting a missing drone battery. The first LLM attempt forgets is_complaint; validation catches it. The second attempt misformats the email; validation catches that too. On the third attempt, the model delivers a clean payload. The customer never notices the retries, your logs capture the entire dance, and your audit trail shows exactly how the final decision emerged.
- Action checklist:
- Wrap every LLM call behind a validator that returns structured errors.
- Log failures with the prompt, raw output, and stack-free error message.
- If retries exceed a threshold, escalate to a human reviewer before executing business logic.
Each bullet locks in a feedback loop that teaches models while keeping humans in the loop when things stay messy.
Schemas as API Dialects
Once you trust your schema, the next challenge is integrating across providers. Instructor, OpenAI’s native JSON modes, Anthropic, Gemini, and Pydantic AI all speak slightly different dialects. Your goal is to keep the schema stable while swapping providers as business constraints change.
Each box on the right can produce a CustomerQuery instance, yet the calling conventions differ. Here's a side-by-side snapshot:
| Provider | Call Pattern | Retry Handling | Notes |
|---|---|---|---|
| Instructor + Anthropic | client = instructor.from_provider("anthropic/<model>", mode=instructor.Mode.ANTHROPIC_TOOLS); client.chat.completions.create(response_model=CustomerQuery, ...) | Built-in | Schema extracted automatically; supports tools, parallel tools, streaming |
| OpenAI (Structured Outputs) | client.beta.chat.completions.parse(model="gpt-5", messages=[...], response_format=CustomerQuery) or client.responses.parse(model="gpt-5", input=[...], response_format=CustomerQuery) | Partial built in | SDK parses to your model and enforces schema; still add Pydantic validators and your own retries for robustness |
| Pydantic AI | agent = Agent('openai:gpt-5', output_type=CustomerQuery) | Built-in | Swappable providers, consistent interface |
The table isn’t trivia; it shapes operational choices. If you need multi-provider redundancy for reliability, Pydantic AI’s abstraction helps. If you want to reuse an existing OpenAI contract, you can still rely on model_validate_json as the final arbiter.
- Action item: Treat your Pydantic models as the lingua franca across providers. When switching APIs, keep the schema constant and adapt only the wrapper layer.
Tool Calling Without Anxiety
Here’s a common multi‑provider orchestration pattern: Gemini to draft a CustomerQuery, GPT‑5 to decide which tool to call, and Claude to author the final support ticket. The only reason this multi‑agent pipeline works is because every handoff runs through Pydantic.
The moment you allow an LLM to call a tool, you inherit the risks of malformed arguments. Picture a tool named check_order_status that expects {"order_id": "ABC-12345"}. Without validation, the model might pass "orderId": "DROP TABLE" and your database engineers will never let you forget it.
import re
from pydantic import BaseModel, Field, field_validator
class CheckOrderStatusArgs(BaseModel):
order_id: str = Field(..., description="Order identifier in format ABC-12345")
@field_validator("order_id")
@classmethod
def enforce_pattern(cls, value: str) -> str:
if not re.fullmatch(r"[A-Z]{3}-\d{5}", value):
raise ValueError("order_id must match pattern ABC-12345")
return value
Every tool schema deserves the same scrutiny: strict patterns, enums for known options, optional fields annotated clearly. When GPT-5 suggests a tool call, you validate the arguments before hitting live systems. If validation fails, you hand the error back to the LLM for repair or fallback to a human.
Practical guardrails:
- Validate before execution – No tool call should touch a database or API until it passes Pydantic checks.
- Log context-rich attempts – Store the prompt, arguments, and error for reproduction.
- Chain validation – Nested models (
SupportTicketcontainingCustomerQueryplusResolutionPlan) keep every layer typed.
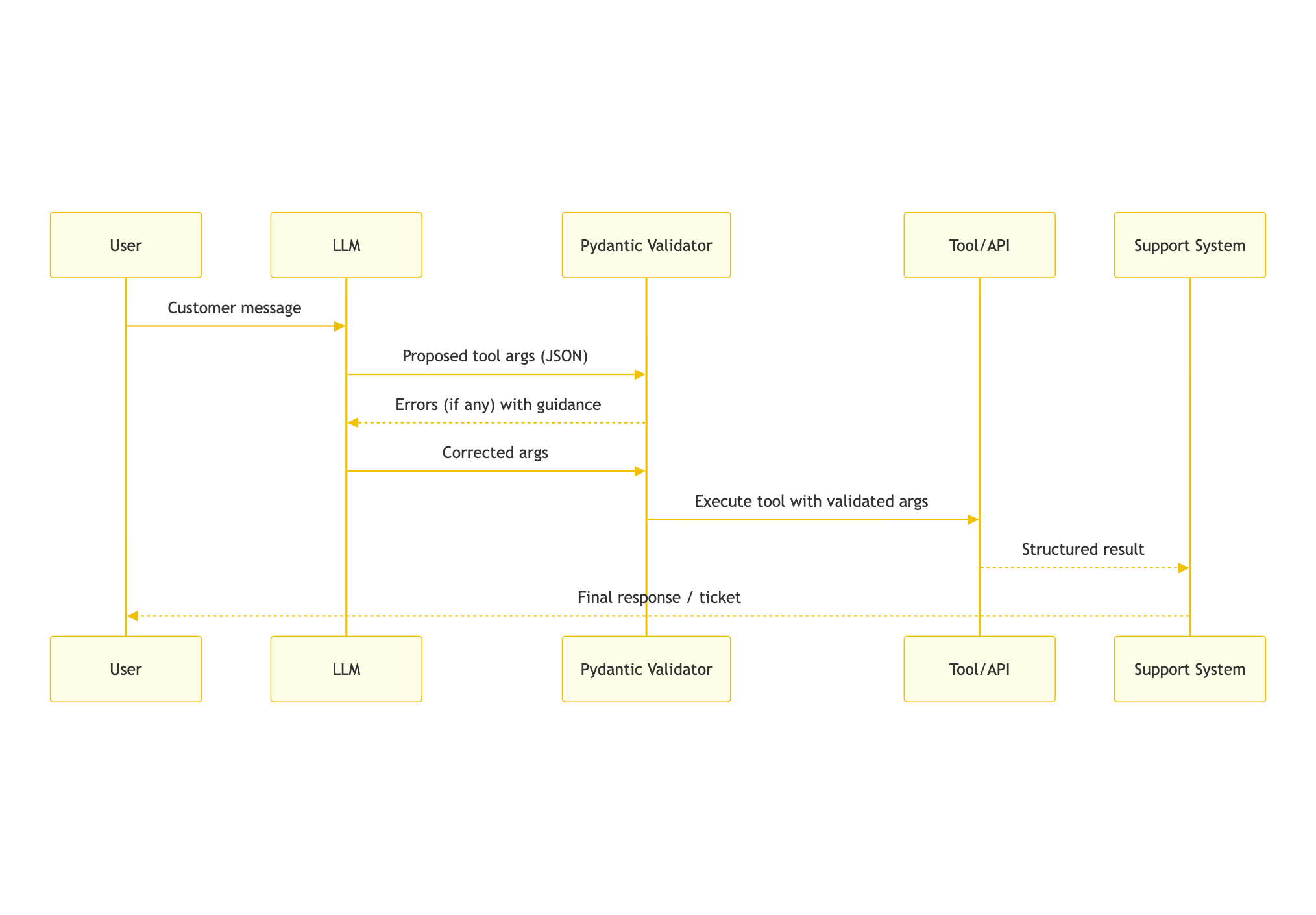
With those patterns in place, multi-agent orchestration moves from anxiety-inducing to auditable.
From Prototype Notebook to Production Flight Recorder
If notebooks are the playground, production is the flight recorder. You need a record of every prompt template, every configuration knob, every model choice that shaped a customer-facing answer. Pydantic models double as configuration stores and logging structures that serialize cleanly.
from datetime import datetime
from typing import List, Optional, Literal
from pydantic import BaseModel, Field
class ResolutionPlan(BaseModel):
steps: List[str]
refund_amount: Optional[float]
escalation_level: Literal["self-serve", "agent", "specialist"]
class SupportTicket(BaseModel):
id: str
received_at: datetime
customer: CustomerQuery
resolution: ResolutionPlan
notes: List[str] = Field(default_factory=list)
Every time your pipeline produces a ticket, you store a serialized SupportTicket alongside the raw prompt and model metadata. That structure becomes your flight recorder: when a compliance audit arrives or a customer challenges a decision, you replay the exact state that led to the response.
For clean storage and debugging, prefer structured dumps:
ticket_json = ticket.model_dump_json(indent=2)
Instrumentation belongs here as well. Track retry counts, validation failures, and latency per provider. Use these metrics to trigger alerts:
if validation_failures_ratio > 0.2:
alert("CustomerQuery validation failing in >20% of requests. Investigate prompt drift.")
You don’t need a full observability platform on day one, but you do need a foothold. Start with structured logs in JSON, then layer dashboards as volume grows. The key is that Pydantic gives you stable, typed events to monitor.
Schema Versioning and Compatibility
Schemas evolve. Treat them like APIs with explicit versions and careful migrations.
from typing import Literal
from pydantic import BaseModel, Field, EmailStr, model_validator
class CustomerQueryV1(BaseModel):
schema_version: Literal["1.0"] = "1.0"
name: str
email: EmailStr
query: str
priority: Literal["low", "medium", "high"]
# Original field name in v1
category: Literal["refund_request", "information_request", "other"]
class CustomerQueryV2(CustomerQueryV1):
schema_version: Literal["1.1"] = "1.1"
# Rename category -> topic (align domain with your taxonomy)
topic: Literal["refund_request", "information_request", "other"] | None = None
category: Literal["refund_request", "information_request", "other"] | None = Field(
default=None, description="Deprecated in 1.1; use 'topic'"
)
@model_validator(mode="before")
@classmethod
def migrate_category(cls, data):
# Accept v1 payloads and normalize to v1.1
if isinstance(data, dict):
# Upgrade schema_version to 1.1 for canonicalization
if data.get("schema_version") == "1.0":
data = {**data, "schema_version": "1.1"}
# If 'topic' is missing but 'category' is present, copy it forward
if data.get("topic") is None and data.get("category") is not None:
data = {**data, "topic": data["category"]}
return data
- Introduce a
schema_versionfield and log it with every event. - When renaming fields, keep the old field temporarily and migrate in a validator.
- Add contract tests that parse historical fixtures to prevent accidental breakage.
Epilogue – Owning the Full Support Ticket
Let’s rewind to our frustrated customer. They submit a form about missing drone parts. Gemini parses the prose into a CustomerQuery, GPT-5 checks whether check_order_status should run, a validated tool call fetches shipment data, and Claude crafts a human-ready SupportTicket. Every transition is mediated by Pydantic: strict enums prevent creative status codes, validators guard against malformed IDs, and nested models record the decision trail.
The payoff is more than fewer incidents. You build a system where product managers can adjust schemas, prompt engineers can update templates, and compliance teams can audit decisions without spelunking through unstructured logs. The model becomes a collaborator, not because it suddenly stopped hallucinating, but because you built a frame that channels its creativity into structured, trustworthy outputs.
Conclusion
Pydantic turns LLM integration from guesswork into an interface. Define schemas first, validate every handoff, and keep a structured record. As providers and tools change, hold the contract steady so behavior stays predictable.
- Model first: define
BaseModelschemas for inputs, tool calls, and outputs before prompts or routing. - Validate every boundary: parse raw JSON, re-validate after transforms, and reject before any side effects.
- Repair with limits: feed
ValidationErrormessages back to the model, cap retries, and escalate when needed. - Instrument by default: log prompt, model ID,
schema_version, and the validated payload; track failure rates and latency. - Plan for change: add
schema_version, write migration validators, and keep contract tests for historical fixtures.
Start with one high-impact flow, ship the schema and validation today, then expand across the pipeline.