
RAG Triad: Building Trust in RAG Through Systematic Evaluation
- Published on
- Authors

- Name
- Arthur Reimus
- @artreimus
Key Takeaways
I. Introduction
In early 2023, a lawyer submitted a brief to the court citing multiple case precedents—except the cases didn't exist. They were hallucinations, fabricated by ChatGPT with such conviction that even the experienced attorney didn't verify them. The result? Court sanctions and a stark reminder of AI's potential for deception.
This isn't an isolated incident. AI systems have shown an unsettling tendency to make things up. Studies suggest large language models hallucinate in 27% of their responses, with factual errors in nearly half of their outputs.
What makes this particularly dangerous is how convincing these hallucinations can be. Like a student crafting an elaborate but false answer rather than admitting ignorance, AI models generate content that sounds factual but is either fabricated or unverifiable. The stakes are high—from healthcare systems suggesting non-existent treatments to financial models fabricating market analyses.
This is where Retrieval-Augmented Generation (RAG) enters the picture. By grounding AI responses in verifiable documents, RAG promises to bring reliability to AI systems. But implementing RAG isn't enough—we need systematic ways to evaluate its effectiveness. Through the RAG Triad framework, we'll discover how to build AI systems that aren't just convincing, but trustworthy.
II. Understanding RAG: A Foundation for Trustworthy AI
What is RAG?
At its core, RAG is like giving an AI a carefully curated reference library before asking it questions. Instead of forcing the model to rely solely on its training data—which can lead to those hallucinations we discussed earlier—RAG first retrieves relevant information from your knowledge base, then uses that to generate accurate answers.
Let's break down how it works:
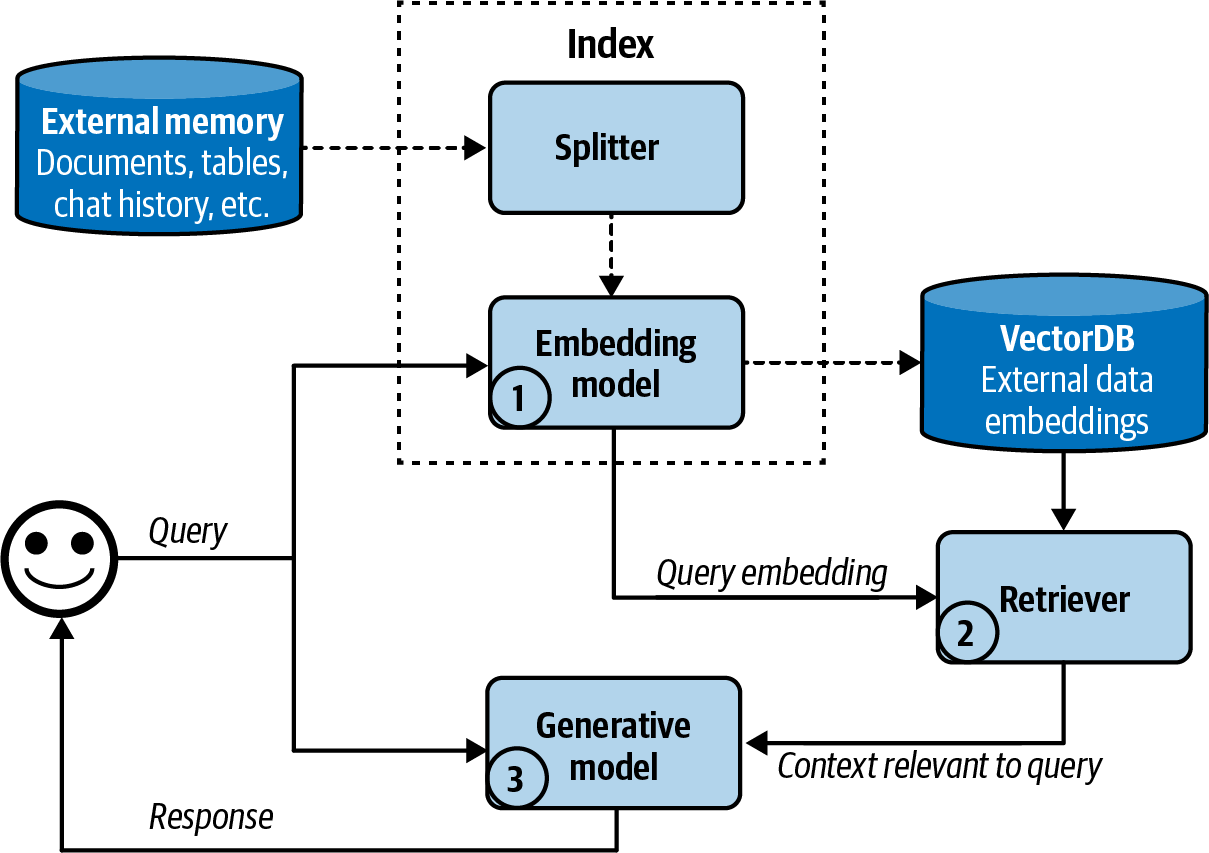
Figure: A high-level view of how an embedding-based, or semantic, retriever works. From "AI Engineering: Building Applications with Foundation Models" (Huyen, 2024).
Core Components:
- External Memory: Your knowledge base—documentation, chat logs, databases, anything you want your AI to reference
- Splitter: Breaks down documents into digestible chunks
- Embedding Model: Converts text into numerical representations that capture meaning
- Vector Database: Stores these embeddings for quick retrieval
- Retriever: Finds the most relevant information for each query
- Generative Model: Creates human-like responses using the retrieved context
How RAG Improves Responses: Think of it like the difference between asking someone to recall a conversation from memory versus having them reference the actual transcript. RAG grounds AI responses in your actual data, making them more accurate and trustworthy.
Real-world Applications
RAG isn't just theoretical—it's transforming how organizations interact with AI. Here are some common applications:
Technical Documentation: Companies use RAG to help developers navigate complex technical documentation. Instead of scrolling through endless pages, developers can ask questions and get precise, contextual answers.
Customer Support: Support teams use RAG to provide accurate responses based on verified solutions and knowledge base articles. The AI can instantly access and synthesize information from thousands of support tickets and documentation pages.
Internal Knowledge Management: Organizations use RAG to make their internal knowledge accessible. Employees can query vast repositories of internal documents, getting accurate answers grounded in company-specific information.
The beauty of RAG is its adaptability. Unlike traditional AI models that require extensive retraining to learn new information, RAG systems can be updated simply by modifying their knowledge base. Add a new document, and the system can immediately use that information in its responses.
But with this power comes responsibility. The quality of RAG responses depends heavily on the quality of your knowledge base—"garbage in, garbage out". This is why systematic evaluation, which we'll discuss in the next section, is crucial for building trust in RAG systems.
III. The RAG Triad: A Framework for Evaluation
Despite RAG's promise in reducing hallucinations, implementing it isn't enough—we need systematic ways to evaluate its effectiveness. Enter the RAG Triad: a comprehensive framework for evaluating RAG systems across three critical dimensions.
The Three Pillars
The RAG Triad consists of three key evaluations that, when combined, provide a robust assessment of a RAG system's reliability:
Context Relevance: This first pillar evaluates whether the retrieved information actually relates to the user's query. Think of it as checking if we're pulling the right books off our library shelves. Irrelevant context can lead to misleading or off-topic responses, even if the generation step is perfect.
Groundedness: Once we have our context, groundedness measures whether the AI's response stays true to this information. Like a good academic paper, every significant claim in the response should be traceable back to the source material. This prevents the model from "going rogue" and inventing facts beyond its retrieved context.
Answer Relevance: The final pillar ensures the response actually addresses the user's question. A response can be perfectly grounded in relevant context but still fail to answer what was asked. This evaluation closes the loop back to the user's intent.
Why All Three Matter
Each pillar addresses a different potential failure mode in RAG systems:
Consider what happens when any pillar is weak:
- Poor Context Relevance means we're working with the wrong information from the start
- Weak Groundedness allows the model to hallucinate despite having good context
- Low Answer Relevance means we might give factual but unhelpful responses
Only when all three metrics score high can we confidently say our RAG system is functioning as intended. It's like a three-legged stool—all legs must be sturdy for the system to be stable.
Common Failure Modes
Understanding how RAG systems can fail helps us appreciate why we need this comprehensive evaluation:
Retrieval Failures:
- Semantic mismatch between query and document embeddings
- Missing or incomplete information in the knowledge base
- Over-retrieval of tangentially related content
Grounding Issues:
- Model "hallucinating" additional details not present in context
- Misinterpreting or misquoting retrieved information
- Combining facts incorrectly across different context pieces
Relevance Problems:
- Providing factual but off-topic responses
- Missing key aspects of multi-part questions
- Getting distracted by interesting but irrelevant context
By systematically evaluating all three aspects, we can identify where our RAG system needs improvement and make targeted enhancements to build more trustworthy AI applications.
Mitigating Failure Modes
Understanding how RAG systems can fail is only half the battle—we need strategies to prevent and address these failures. Here's how to mitigate issues across each pillar of the RAG triad:
Improving Context Relevance:
- Implement hybrid search combining both semantic and keyword-based approaches
- Fine-tune embedding models on domain-specific data
- Use chunking strategies that preserve semantic meaning
- Add metadata and tags to improve retrieval accuracy
Enhancing Groundedness:
- Implement fact-checking by breaking responses into atomic claims
- Use multiple retrievers and cross-reference their results
- Add explicit source attribution requirements
- Set up automated verification against known facts
Boosting Answer Relevance:
- Implement query rewriting to better capture user intent
- Use multi-step reasoning with intermediate validations
- Add explicit answer quality checks
- Maintain conversation context to track multi-turn queries
Leveraging Prompt Engineering:
- Design system prompts that enforce strict grounding in retrieved context
- Use chain-of-thought prompting to make reasoning explicit
- Implement self-critique prompts for validation
- Structure prompts to separate reasoning from response generation
- Add examples demonstrating proper source attribution and fact-checking
Additionally, system-wide improvements can help prevent failures across all three dimensions:
- Monitoring and Logging: Track each component's performance metrics to identify degradation early
- Fallback Mechanisms: Design graceful degradation paths when confidence is low
- Human-in-the-Loop: Incorporate expert review for critical applications
- Continuous Evaluation: Regularly test against evolving benchmarks and edge cases
Remember that mitigation strategies should be tailored to your specific use case and failure patterns. What works for a customer support system might not be appropriate for a medical diagnosis assistant.
IV. Implementing the RAG Triad
Let's move from theory to practice by implementing the RAG Triad using TruLens, a powerful open-source library for evaluating and tracking LLM-based applications. We'll create a complete RAG system from scratch and show how to evaluate it using the three pillars we discussed.
Setting Up Our Environment
First, let's install the required packages:
!pip install trulens-providers-litellm chromadb litellm
Then set up our environment variables:
import os
os.environ["WATSONX_URL"] = "" # Base URL of your WatsonX instance
os.environ["WATSONX_API_KEY"] = "" # IBM cloud API key
os.environ["WATSONX_PROJECT_ID"] = "" # Project ID of your WatsonX instance
Setting Up Our Knowledge Base
Let's create a simple knowledge corpus about different types of pets and their care:
dog_info = """
Dogs are one of the most popular pets worldwide. They require daily exercise, regular veterinary care,
and proper training. Most dogs need to be walked at least once a day and benefit from social interaction
with both humans and other dogs.
"""
cat_info = """
Cats are independent pets that are well-suited for indoor living. They are known for their grooming habits
and typically live 12-18 years. Cats require a litter box, regular feeding, and annual veterinary check-ups,
but generally need less direct supervision than dogs.
"""
fish_info = """
Fish are relatively low-maintenance pets that can be kept in aquariums. Proper water temperature and chemistry
are essential for their health. Different species have varying care requirements, with tropical fish needing
heated tanks while goldfish can thrive in cooler water.
"""
hamster_info = """
Hamsters are small rodents that make popular starter pets. They are nocturnal animals that live 2-3 years
on average. They need a secure cage, exercise wheel, proper bedding, and a varied diet of hamster food
supplemented with fresh vegetables.
"""
Creating the Vector Store
We'll use ChromaDB as our vector store, which by default uses the Sentence Transformers all-MiniLM-L6-v2 model for embeddings:
import chromadb
from chromadb.utils import embedding_functions
default_ef = embedding_functions.DefaultEmbeddingFunction()
chroma_client = chromadb.Client()
vector_store = chroma_client.get_or_create_collection(
name="Pets",
embedding_function=default_ef
)
# Add our documents to the vector store
vector_store.add("dog_info", documents=dog_info)
vector_store.add("cat_info", documents=cat_info)
vector_store.add("fish_info", documents=fish_info)
vector_store.add("hamster_info", documents=hamster_info)
Building Our RAG Application
Now let's create a custom RAG class with TruLens instrumentation:
from trulens.apps.custom import instrument
from trulens.core import TruSession
import litellm
session = TruSession()
session.reset_database() # Clear any previous evaluation data
class RAG:
@instrument
def retrieve(self, query: str) -> list:
"""
Retrieve relevant text from vector store.
"""
results = vector_store.query(query_texts=query, n_results=4)
return [doc for sublist in results["documents"] for doc in sublist]
@instrument
def generate_completion(self, query: str, context_str: list) -> str:
"""
Generate answer from context.
"""
if len(context_str) == 0:
return "Sorry, I couldn't find an answer to your question."
completion = litellm.completion(
model="gpt-3.5-turbo",
temperature=0,
messages=[
{
"role": "user",
"content": f"We have provided context information below. \n"
f"---------------------\n"
f"{context_str}"
f"\n---------------------\n"
f"Given this information, please answer the question: {query}",
}
],
).choices[0].message.content
return completion if completion else "Did not find an answer."
@instrument
def query(self, query: str) -> str:
context_str = self.retrieve(query=query)
completion = self.generate_completion(query=query, context_str=context_str)
return completion
rag = RAG()
Implementing the Three Pillars with TruLens
Now we'll set up our evaluation framework using TruLens feedback functions with LiteLLM:
import numpy as np
from trulens.core import Feedback
from trulens.providers.litellm import LiteLLM
provider = LiteLLM(model_engine="watsonx/mistralai/mistral-large")
# 1. Context Relevance
f_context_relevance = (
Feedback(
provider.context_relevance_with_cot_reasons,
name="Context Relevance"
)
.on_input()
.on(Select.RecordCalls.retrieve.rets[:])
.aggregate(np.mean)
)
# 2. Groundedness
f_groundedness = (
Feedback(
provider.groundedness_measure_with_cot_reasons,
name="Groundedness"
)
.on(Select.RecordCalls.retrieve.rets.collect())
.on_output()
)
# 3. Answer Relevance
f_answer_relevance = (
Feedback(
provider.relevance_with_cot_reasons,
name="Answer Relevance"
)
.on_input()
.on_output()
)
Adding Guardrails
TruLens allows us to add guardrails to prevent hallucinations at inference time:
from trulens.core.guardrails.base import context_filter
# Feedback function for guardrail (returns only score, not reasons)
f_context_relevance_score = Feedback(
provider.context_relevance,
name="Context Relevance"
)
class FilteredRAG(RAG):
@instrument
@context_filter(
feedback=f_context_relevance_score,
threshold=0.75,
keyword_for_prompt="query",
)
def retrieve(self, query: str) -> list:
"""
Only returns context that meets the relevance threshold
"""
results = vector_store.query(query_texts=query, n_results=4)
if "documents" in results and results["documents"]:
return [doc for sublist in results["documents"] for doc in sublist]
else:
return []
filtered_rag = FilteredRAG()
Running and Evaluating Our RAG System
Let's wrap our RAG with TruLens and run some test queries:
from trulens.apps.custom import TruCustomApp
# Wrap our RAG with TruLens
tru_rag = TruCustomApp(
rag,
app_name="RAG",
app_version="base",
feedbacks=[f_groundedness, f_answer_relevance, f_context_relevance],
)
# Run test queries
with tru_rag as recording:
rag.query("What wave of coffee culture is Starbucks seen to represent in the United States?")
rag.query("What programs is WSU known for?")
rag.query("When was the Space Needle built?")
Viewing Evaluation Results
TruLens stores all evaluation results in a SQLite database and provides a convenient web dashboard to view them. You can launch the dashboard with:
from trulens.dashboard import run_dashboard
run_dashboard(session)
Iterative Improvement
The real power of the RAG Triad comes from using these evaluations to improve your system. For example, if you notice:
- Low context relevance scores: Adjust your retrieval strategy or chunk size
- Poor groundedness: Modify your prompt to emphasize using only provided context
- Low answer relevance: Refine your prompt to better focus on the query
For a complete implementation and more advanced features, we recommend reading the TruLens documentation. The library provides extensive tools for tracking, evaluating, and improving your RAG applications.
Remember: The goal isn't just to implement these evaluations, but to use them to iteratively improve your RAG system. Monitor the metrics, identify failure patterns, and adjust your implementation accordingly.
V. Conclusion
As AI systems become increasingly integrated into critical decision-making processes, the need for trustworthy and reliable outputs has never been more crucial. The RAG Triad framework offers a systematic approach to building this trust through comprehensive evaluation across context relevance, groundedness, and answer relevance.
By implementing these three pillars of evaluation, organizations can:
- Detect and prevent AI hallucinations before they impact users
- Build confidence in AI-generated responses through verifiable sources
- Continuously improve their RAG systems through targeted refinements
- Create AI applications that users can genuinely trust and rely upon
The journey to trustworthy AI isn't about eliminating uncertainty—it's about managing it systematically. Through careful evaluation and iterative improvement using frameworks like the RAG Triad, we can build AI systems that not only appear intelligent but are demonstrably reliable and worthy of our trust.
References
Lawyer apologizes for fake court citations from ChatGPT (CNN)
Chatbots May 'Hallucinate' More Often Than Many Realize (NY Times)
Huyen, C. AI Engineering: Building Applications with Foundation Models, O'Reilly Media, 2024
Image Attribution
Harvest Fields in Westerham, Kent, 1880-1910 by Helen Allingham