
Key Takeaways
- An LLM Wiki is an agent-maintained Markdown knowledge base where raw sources stay immutable and useful answers write back into durable pages.
- The shift is from one-off retrieval to compounding knowledge: each ingest, contradiction, and good answer improves the next session.
- Register raw sources deterministically before synthesis: stable source IDs, hashes, permissions, status, and change reports.
- Treat
AGENTS.md,purpose.md,index.md, andlog.mdas the operating system for the wiki.
An LLM Wiki is an idea Andrej Karpathy sketched in his April 2026 "LLM Wiki" gist: a knowledge base that an agent maintains as part of its work. Raw sources stay immutable. The agent reads them, compiles their claims into interlinked Markdown pages, and writes useful answers back into the corpus instead of letting them disappear into chat history.
That sounds small until you notice what changed: the output of an agent session is no longer just an answer. The output is a better knowledge base.
Traditional RAG treats documents as a pile of chunks to search at query time. That works, but the system keeps rediscovering the same context. Ask a subtle question that depends on five sources, and the model has to find, reconcile, and explain those sources again.
An LLM Wiki turns that reconciliation into a durable artifact. The comparison table, contradiction note, entity summary, decision record, and corrected explanation can all become pages. The next session starts from the compiled knowledge, not from zero.
This is why the pattern matters for agents. Agents do not just need bigger context windows. They need a way to keep learning inside a project without smearing every previous conversation into an opaque memory blob. An LLM Wiki gives them a file-backed working memory with source IDs, diffs, logs, review states, and human-readable pages.
Markdown is not the magic part. Writeback is.
Since Karpathy published the gist on April 4, 2026, the pattern has turned into a small ecosystem. The useful implementation lessons are distributed: nvk/llm-wiki emphasizes isolated topic wikis, Ss1024sS/LLM-wiki shows deterministic raw intake and stale reports, Synthadoc adds candidate staging, routing, audit trails, and linting, and OpenKB frames the wiki as a compiled artifact with index, log, and lint loops.
This is how I would build the first useful version.
Build one topic wiki first
The first design choice is scope. Start with one topic, not one giant wiki for your whole life, company, and research backlog.
The nvk/llm-wiki implementation makes this explicit with isolated topic wikis and a lightweight hub. That is the right default. Cross-topic context sounds convenient until the agent starts mixing unrelated definitions, stale assumptions, and duplicate entity pages.
Use a layout like this:
wiki-hub/
_index.md
log.md
topics/
agent-evaluation/
AGENTS.md
purpose.md
raw/
sources/
assets/
manifests/
sources.csv
raw_index.json
intake_report.md
wiki/
index.md
log.md
dashboard.md
topics/
entities/
decisions/
contradictions/
answers/
candidates/
reports/
output/
Four files matter immediately:
purpose.md: the boundary of the wiki. What belongs, what does not, and what vocabulary to use.AGENTS.md: the agent operating contract. How to ingest, answer, write back, lint, and review.wiki/index.md: the content map. The agent reads this first.wiki/log.md: the timeline. Every ingest, query, writeback, and lint pass lands here.
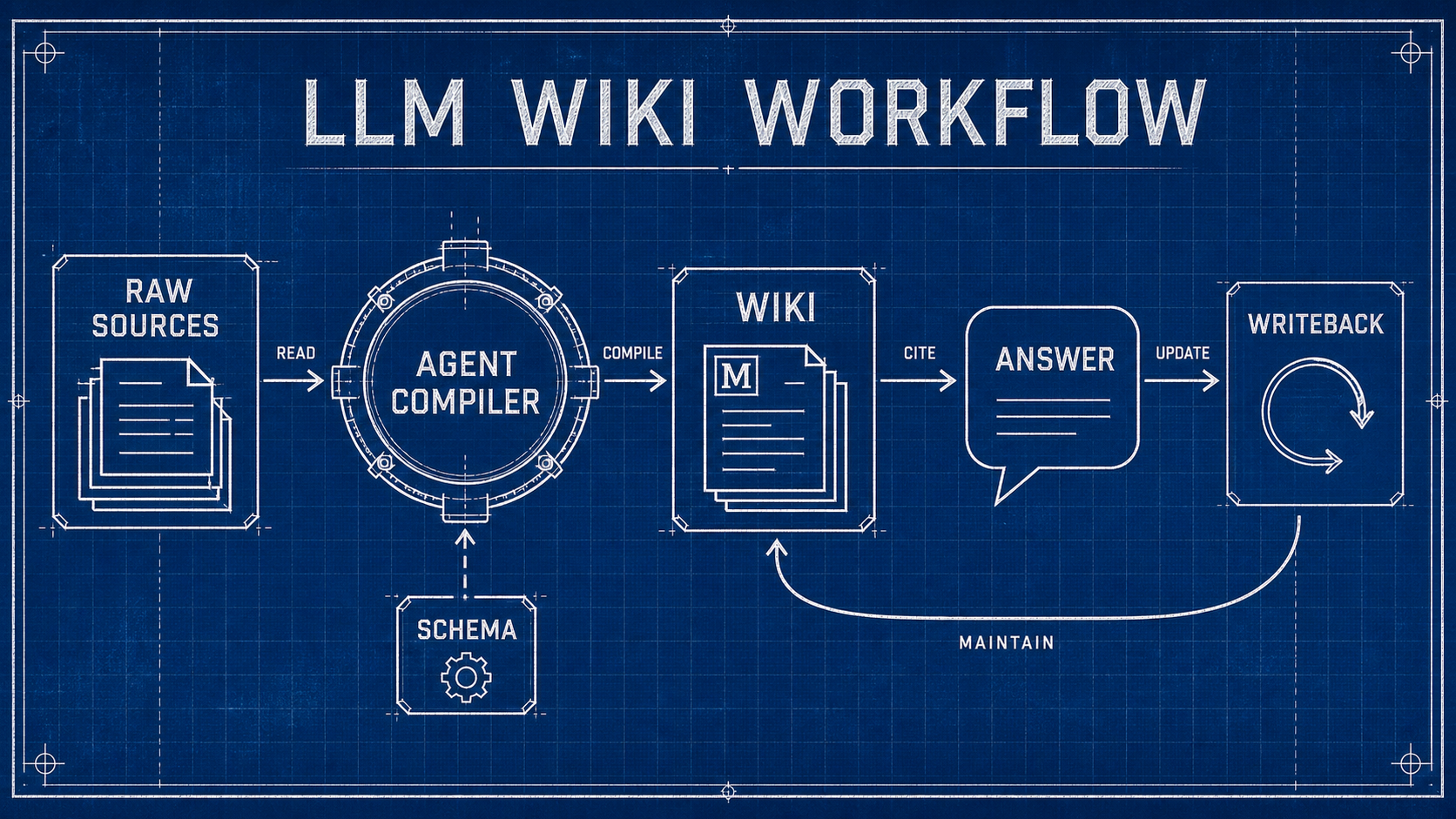
The useful unit is not a chat answer. It is a maintained knowledge artifact that can be read, linked, checked, and revised later.
This is intentionally file-backed. The wiki should be easy for an agent to edit, easy for a human to review, and easy for git to diff.
Register raw sources before synthesis
Most failed LLM Wiki attempts start by asking the model to summarize a folder. That works for five files and falls apart at fifty.
Do deterministic intake first. The LLM should spend tokens on synthesis, not clerical source registration.
Your manifests/sources.csv should be boring:
source_id,title,origin,path,source_hash,kind,accessed_at,owner,permission,status
src_0001,LLM Wiki gist,https://gist.github.com/karpathy/442a6bf555914893e9891c11519de94f,raw/sources/karpathy-llm-wiki.md,4f91c2a8,markdown,2026-05-16,arthur,public,active
src_0002,Evaluation planning notes,local,raw/sources/eval-planning-2026-05-14.md,a12bd77e,markdown,2026-05-16,arthur,internal,new
The Ss1024sS ingest pipeline is worth copying conceptually: scan raw files, compute hashes, detect duplicates, infer cheap metadata locally, report what is new or stale, and only then ask the LLM to compile. Synthadoc and OpenKB make similar bets with audit records, source handling, and lint reports.
Raw sources stay immutable. If a source changes, record a new hash and mark dependent pages stale. Do not let the agent quietly overwrite the evidence.
Define page types before writing pages
Most wikis go bad because every page has the same shape. An LLM Wiki should be more mechanical.
Use a small set of page types:
topic: a concept or area, such ascontext-engineering.mdorllm-evaluation.md.entity: a person, company, model, library, paper, product, or project.decision: a choice that was made, with options considered and evidence.contradiction: two or more sources that disagree or changed over time.answer: a useful response from a session that deserves to become durable context.candidate: a page the agent drafted but should not trust yet.
Give every page frontmatter. Keep it simple enough that an agent will maintain it without heroic prompting.
---
type: topic
owner: arthur
status: draft
last_verified_at: 2026-05-16
source_ids:
- src_0007
source_hashes:
- 4f91c2a8
confidence: medium
permissions: internal
review_status: draft
---
Then standardize the body: current summary, evidence, open questions, and related pages.
# Context Engineering
## Current Summary
What we believe right now.
## Evidence
- `src_0007`: what the source says.
- `src_0012`: what changed or confirmed the claim.
## Open Questions
- What still needs verification?
## Related Pages
- [[entities/anthropic]]
- [[decisions/agent-memory-format]]
This looks fussy until the third week, when you ask the agent what changed and it can answer without rereading every PDF, transcript, and planning thread.
Put the workflow in AGENTS.md
An LLM Wiki lives or dies by its instruction file. The agent needs explicit commands, not vibes.
Write the contract around five operations:
# LLM Wiki Operating Contract
1. Ingest: register the source, read `purpose.md`, update existing pages first,
create contradictions, stage low-confidence pages in `wiki/candidates/`, and log the diff.
2. Answer: read `wiki/index.md`, open relevant pages, check raw sources for important claims,
cite page paths and source IDs, and say when the wiki is thin.
3. Write back: turn useful answers into page updates, answer notes, decisions, or candidates.
4. Lint: report stale hashes, orphan pages, uncited claims, duplicate pages, permission leaks,
old candidates, and contradictions without owners.
5. Review: edit drafts directly, but propose diffs for reviewed, high-confidence, or
permission-sensitive pages.
That contract is more important than the folder layout. It turns the model from a summarizer into a maintainer.
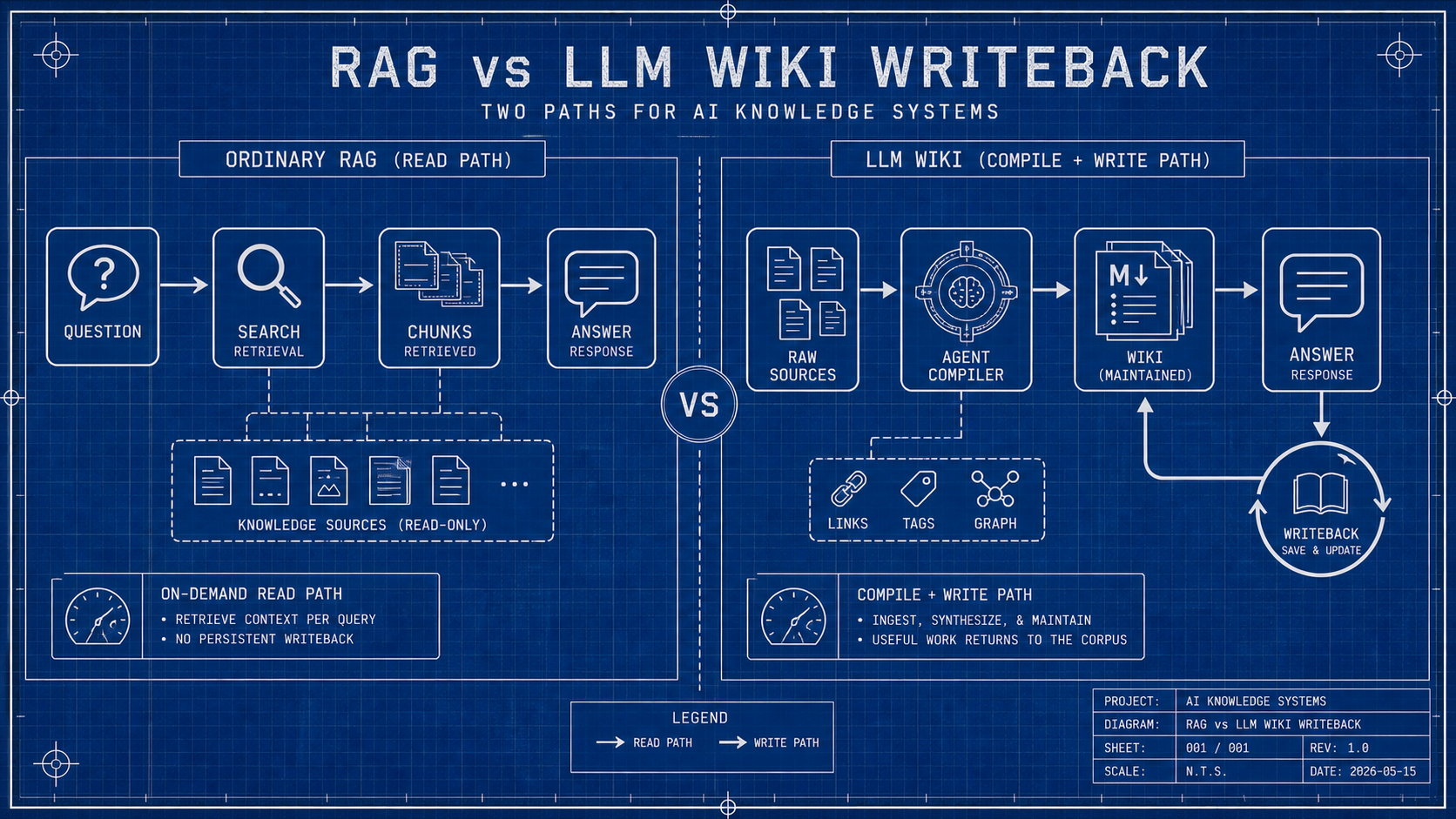
RAG repeats a read path per query. LLM Wiki adds a write path, so useful analysis can return to the maintained corpus.
Make ingest produce a diff, not a summary
The original gist says a single source might touch 10 to 15 wiki pages. OpenKB's README repeats that same behavior as part of its compilation loop: one document updates summaries, concepts, the index, and the log. That is the mental model you want.
The ingest flow should end with changed files, not a floating summary in chat.
For a new source, ask the agent to return a structured ingest report:
type IngestReport = {
sourceId: string
touchedPages: string[]
createdPages: string[]
contradictions: string[]
candidatePages: string[]
unresolvedQuestions: string[]
}
The implementation can be as manual as a Codex or Claude Code session:
Ingest `raw/sources/evals-paper.md` into the LLM Wiki.
Follow `AGENTS.md`.
Prefer updating existing topic and entity pages over creating duplicates.
At the end, show the source ID, changed pages, contradictions, and questions.
The agent should compare the new source against existing pages. New claims update the relevant page. Contradictions create a contradiction page or note. Reinforcing evidence adds another citation. Low-confidence synthesis goes into wiki/candidates/, not the main search path.
The log entry should be predictable:
## 2026-05-16 src_0041 ingest
- Source: `src_0041`, "Evaluation patterns for production agents"
- Changed:
- `wiki/topics/agent-evaluation.md`
- `wiki/entities/langsmith.md`
- Created:
- `wiki/contradictions/eval-pass-rate-vs-task-success.md`
- Candidates:
- `wiki/candidates/task-success-benchmarking.md`
- Open questions:
- Need production data before endorsing pass rate as a release gate.
The log is not for humans to lovingly browse. It is so a future agent can grep history and understand why a page changed.
Make answers eligible for writeback
The most valuable wiki updates often come from questions, not ingests.
Suppose you ask:
Compare our current agent memory approach with the LLM Wiki pattern.
Use the wiki and cite raw sources where needed.
If the comparison should become durable, propose a writeback target.
The answer should include normal prose, but it should also include a maintenance section:
type AnswerMaintenance = {
citedPages: string[]
citedSources: string[]
proposedWritebacks: {
targetPath: string
reason: string
summary: string
}[]
}
This is the shift that makes the wiki compound. A good answer should become a decision page, a topic update, a comparison table, or a short answer note.

The operating contract should make each agent action inspectable: source IDs, citations, diffs, lint reports, and log entries.
The user should still approve important diffs. Direct writes are fine for draft notes. They are a bad default for policy pages, customer facts, and anything with permission boundaries.
The wiki should be editable, not magical
Let the agent draft updates, but keep the raw sources immutable and the git diff visible. The system earns trust when a human can inspect exactly which claims were added, changed, or retired.
Keep index.md deliberately small
Karpathy's gist says index.md can work surprisingly well around 100 sources and hundreds of pages. That only holds if the index is maintained like a map, not dumped like a sitemap.
Use it to point at the highest-value entry points:
# Wiki Index
## Start Here
- [[topics/context-engineering]]
- [[topics/agent-evaluation]]
- [[decisions/agent-memory-format]]
## Active Contradictions
- [[contradictions/retrieval-vs-writeback]]
- [[contradictions/eval-pass-rate-vs-task-success]]
## Recently Changed
- 2026-05-16: [[topics/llm-wiki]]
- 2026-05-15: [[entities/qmd]]
Keep every entry short: link, one-line purpose, source count, last verified date if useful.
If the index gets noisy, split by branch: indexes/entities.md, indexes/decisions.md, indexes/contradictions.md, and a small routing.md. Newer implementations add routing for a reason. Once you have hundreds or thousands of pages, the agent should choose a branch before searching.
Add search only after the wiki has shape
Search is useful once the wiki is too large to navigate from index.md. It should not replace the maintained pages.
The read path should look like this:
- Read
wiki/index.md. - Search Markdown pages if the index is insufficient.
- Open the most relevant wiki pages.
- Check raw sources only for disputed, stale, permission-sensitive, or high-impact claims.
- Answer with citations.
- Propose writeback if the answer creates durable synthesis.
Karpathy's gist points at qmd, an on-device Markdown search engine. Its current README exposes keyword search, vector search, hybrid query, structured JSON/file outputs for agents, and an MCP server. That is the right kind of tool: search helps the agent find maintained pages, but the wiki remains the artifact.
Use search for retrieval. Use the wiki for synthesis.
Run a wiki lint pass every few sessions
An LLM Wiki needs housekeeping. Otherwise it slowly becomes normal documentation with better branding.
Ask the agent to lint for:
- Pages missing
source_ids. - Pages missing
last_verified_at. - Pages not reachable from
wiki/index.md. - Pages whose
source_hashesno longer matchmanifests/sources.csv. - Duplicate topics with overlapping claims.
- Contradictions without owner or next action.
- Candidate pages older than a review window.
- Public pages citing internal or private sources.
- High-confidence pages with only one weak source.
Then make the lint report actionable:
Run a lint pass on the LLM Wiki.
Do not rewrite pages yet.
Return a table with path, problem, severity, and recommended fix.
This matters because the main failure mode is not that the wiki is empty. The failure mode is that it becomes stale, overconfident, or permission-blind while still looking authoritative.
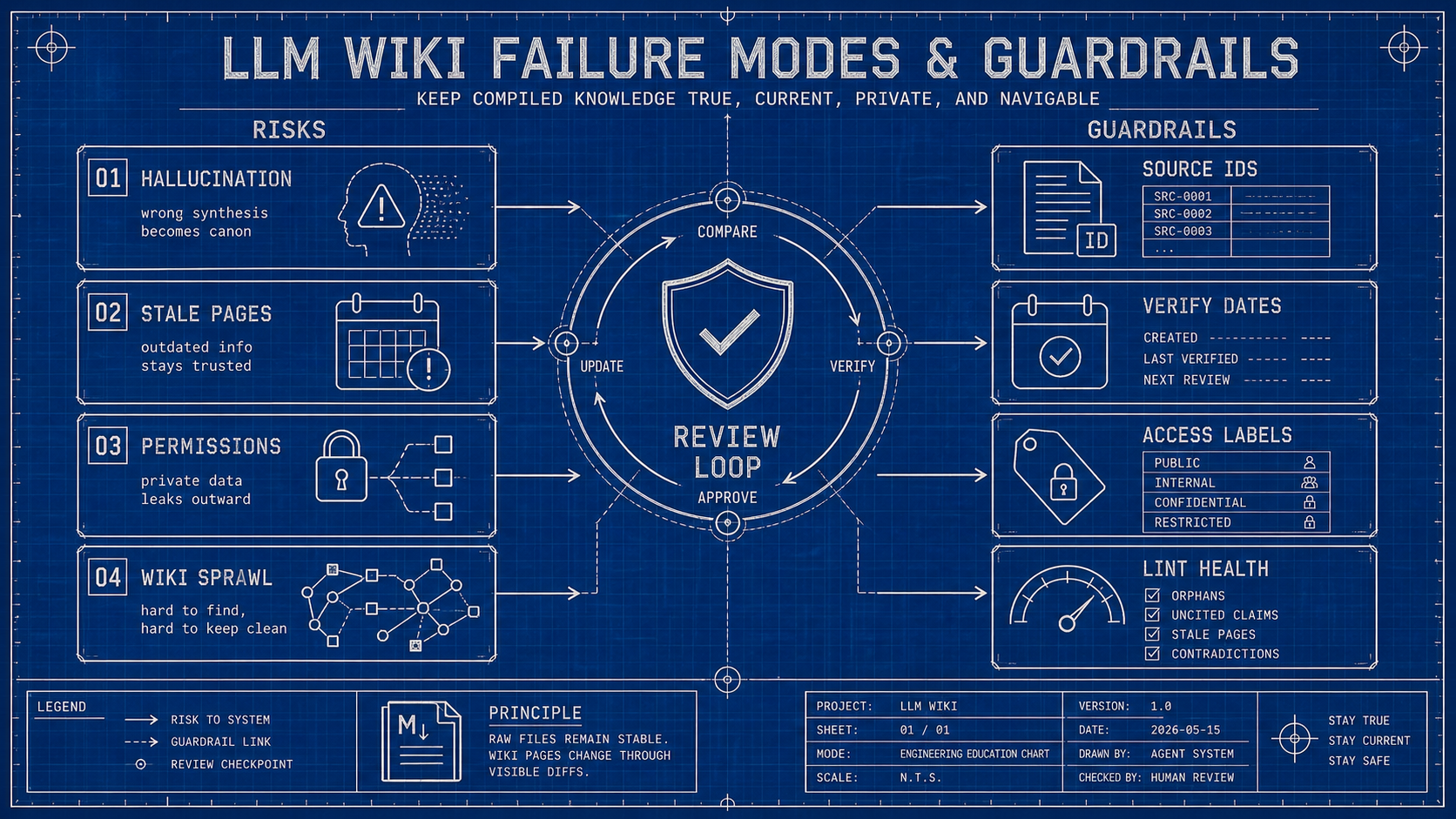
The boring controls are the important ones: source IDs, verification dates, access labels, and lint health checks keep compiled knowledge from quietly becoming wrong.
A good first milestone
Build the first version in this order:
- Pick one topic and write
purpose.md. - Create the folder layout.
- Add
manifests/sources.csvandmanifests/raw_index.json. - Write
AGENTS.mdwith ingest, answer, writeback, candidate, lint, and review rules. - Register five real sources with stable IDs and hashes.
- Compile those sources into wiki pages.
- Create
wiki/index.mdfrom the compiled pages. - Ask three real questions.
- Write back the useful answers.
- Run a lint pass and fix the obvious problems.
If that feels valuable, add search. If it does not feel valuable, a vector database would not have saved it.
The test is simple: after three sessions, can the agent answer "what did we already learn?" without you replaying the whole history?
If the answer is yes, you have something more useful than a chat transcript. You have a wiki that compounds.