Gemma 4: Open Models for Edge and Agent Workflows
- Published on
- Authors

- Name
- Arthur Reimus
- @artreimus
Key Takeaways
- Gemma 4 is best understood as a deployment ladder, not a single flagship model.
- E2B/E4B target edge agents with PLE, 26B A4B targets latency with MoE, and 31B dense targets maximum quality.
- Apache 2.0 changes the adoption story: teams can fine-tune, modify, and commercially deploy without the old Gemma-specific license friction.
- The useful lesson for builders is architectural fit: context length, visual token budgets, active parameters, and runtime support matter more than leaderboard rank.
Gemma 4 is not interesting because Google made another open model bigger.
It is interesting because the family exposes the deployment tradeoffs directly: edge memory, active parameters, long context, visual token budgets, and dense quality are split across different models instead of hidden behind one leaderboard number.
The license matters too. Gemma 4 ships under Apache 2.0, which moves the release out of the awkward "open weights, but read the custom license carefully" category and into normal commercial engineering territory.
That is the right shape for agent systems. A local assistant on a phone does not need the same model as a server-side coding agent. A batch document workflow does not have the same latency target as an on-device voice interface. Gemma 4 accepts those differences instead of pretending one model shape can cover everything.
A technical deployment plate for Gemma 4: edge models, PLE, sparse routing, dense reasoning, and runtime targets in one system view.
The public launch material describes Gemma 4 as Google DeepMind's most capable open model family to date, built from Gemini 3 research and released under Apache 2.0 (Google launch blog). The official model card fills in the useful engineering numbers: E2B and E4B for edge, 26B A4B as a sparse MoE, and 31B as the dense quality model (Gemma 4 model card).
The useful question is not "Which one is biggest?" It is "Which model shape matches the job?"
Gemma 4 is a deployment ladder
Gemma 4 ships as four related models. A simple way to read the lineup is two edge models and two workstation or server models:
| Model | Architecture | Context | Modalities | Design center |
|---|---|---|---|---|
| E2B | Dense effective model with PLE | 128K | Text, image/video frames, audio in; text out | Phones, tablets, laptops, IoT |
| E4B | Larger dense effective model with PLE | 128K | Text, image/video frames, audio in; text out | Stronger on-device agents |
| 26B A4B | Mixture of experts | 256K | Text and image/video frames in; text out | Low-latency reasoning |
| 31B dense | Dense model | 256K | Text and image/video frames in; text out | Maximum quality and fine-tuning |
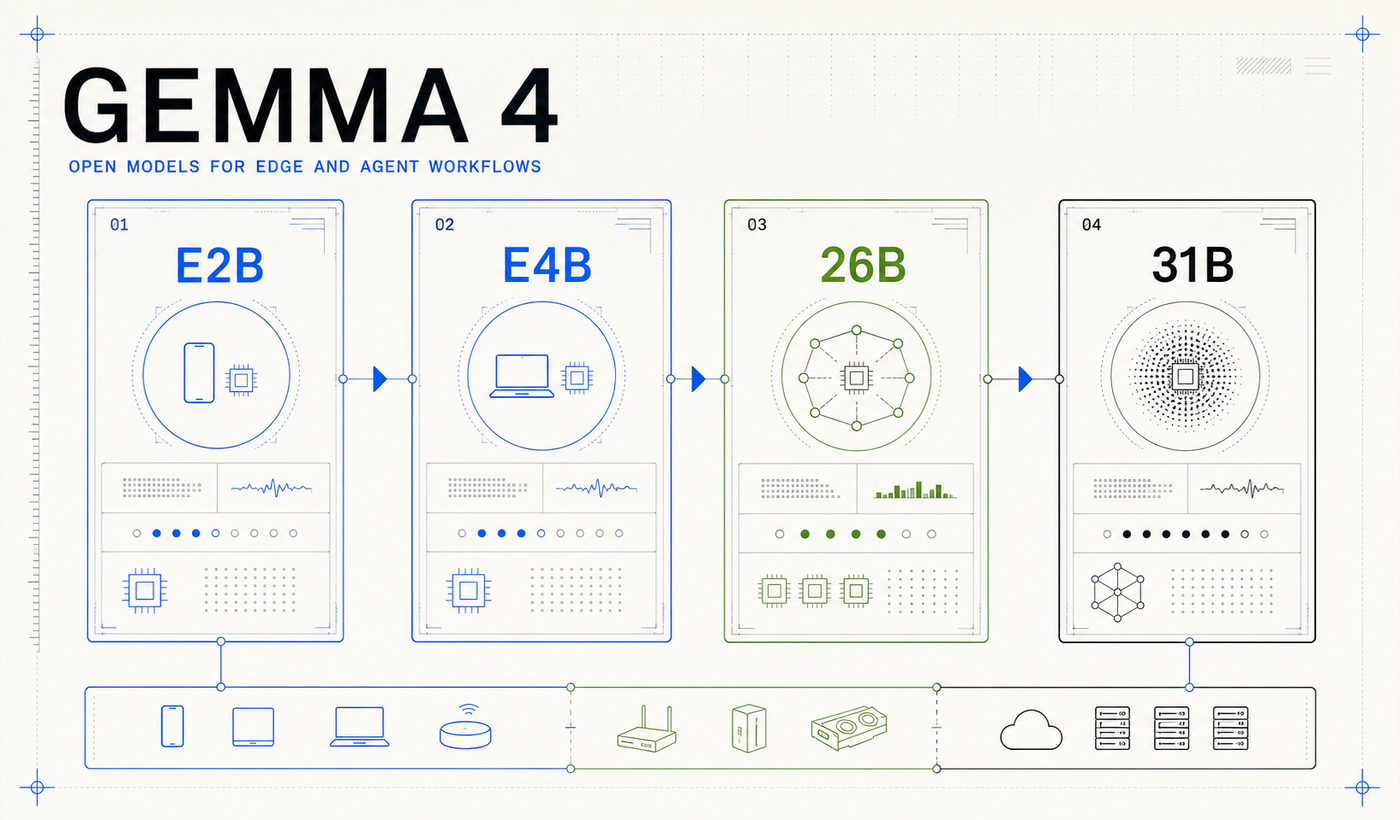
The family is segmented by deployment target: edge memory, on-device quality, sparse latency, and dense reasoning.
Google reported the 31B dense model at #3 and the 26B model at #6 on Arena AI's text leaderboard as of 2026-04-01. That is useful context, but it is not the most important part of the release.
The more useful engineering split is active cost. The official model card lists 25.2B total parameters, 3.8B active parameters, 128 total experts, 8 active experts, and one shared expert for the 26B A4B model. In practice, the 31B is the raw-quality model, while the 26B A4B is the practical latency model.
The smaller E2B and E4B models solve a different problem. They are built around on-device memory pressure and audio-capable multimodality. The "E" means effective parameters: E2B has 2.3B effective parameters and 5.1B total parameters with embeddings, while E4B has 4.5B effective parameters and 8B total parameters with embeddings.
That language can sound like marketing unless you look at PLE.
The release also includes pre-trained and instruction-tuned variants, which matters for teams that want to evaluate the base model for fine-tuning instead of only using the chat model as-is.
Which Gemma 4 model should you use?
For a product team, the family maps to a straightforward decision tree.
Use E2B when the product must run locally, offline, or inside a mobile or IoT memory budget. It is the right starting point for private assistants, embedded workflows, lightweight voice features, and local data extraction where sending data to an API is not acceptable.
Use E4B when the same on-device constraints apply but the task needs more headroom. This is the model to try when E2B is almost good enough but struggles with reasoning depth, multi-step instructions, or messy multimodal inputs.
Use 26B A4B when latency and throughput matter but the system still needs advanced reasoning. This is the most interesting agent-serving candidate: enough capacity for tool use and coding-like workflows, but sparse enough to avoid dense-model cost on every token.
Use 31B dense when quality matters most, especially for complex reasoning, coding, evaluation, and fine-tuning baselines. The dense model is the clean foundation when latency is secondary to correctness.
The four architecture bets behind Gemma 4
Gemma 4 is best read as the next step in a cumulative engineering line rather than as an isolated release.
The original Gemma paper established the public open-model family built from Gemini research and described the training, safety, and evaluation framing for the first 2B and 7B models (Gemma paper). Gemma 2 made practical efficiency a central theme with grouped-query attention, interleaved local-global attention, and model-size choices aimed at strong quality per unit of compute (Gemma 2 paper). Gemma 3 pushed that direction into long-context and multimodal models, including a 128K context window, vision support, and a local/global attention pattern designed to keep long-context inference practical (Gemma 3 Technical Report).
Gemma 4 turns that lineage into four deployment bets.
Long context is treated as a memory problem
The Gemma 4 dense models keep the decoder-only transformer shape, but the attention path is tuned for long context.
The official model card describes a hybrid attention mechanism: local sliding-window layers for cheaper nearby context, plus full global attention layers for sequence-wide integration. The smaller dense models use 512-token sliding windows, while the larger dense and MoE models use 1,024-token windows. The final layer is always global, so the last representation can still gather information across the full context.
Gemma 4 adds more long-context pressure valves. The model card says global layers use unified Keys and Values plus Proportional RoPE. Hugging Face's Transformers integration exposes the implementation knobs behind that direction: grouped-query attention parameters, a larger global attention head dimension, optional key/value tying, and a shared KV-cache setting where later layers can reuse key-value projections instead of recomputing them.
The practical reading is simple: long context is not free. Architecture has to decide when local context is enough, where global awareness is worth paying for, and which KV-cache costs can be removed without giving up too much quality.
Engineering rule
Long context should be treated as a systems budget, not as permission to pass everything. Gemma 4 makes the budget larger, but the hybrid attention and KV-cache optimizations still exist because full attention everywhere is too expensive.
MoE makes the 26B model the latency option
The 26B A4B model is the first MoE model in the Gemma family.
In a dense feed-forward block, every token pays for the same feed-forward network. In the Gemma 4 MoE variant, that standard feed-forward path is replaced with routed experts: 128 total experts, eight selected by the router for each token, plus one always-on shared expert.
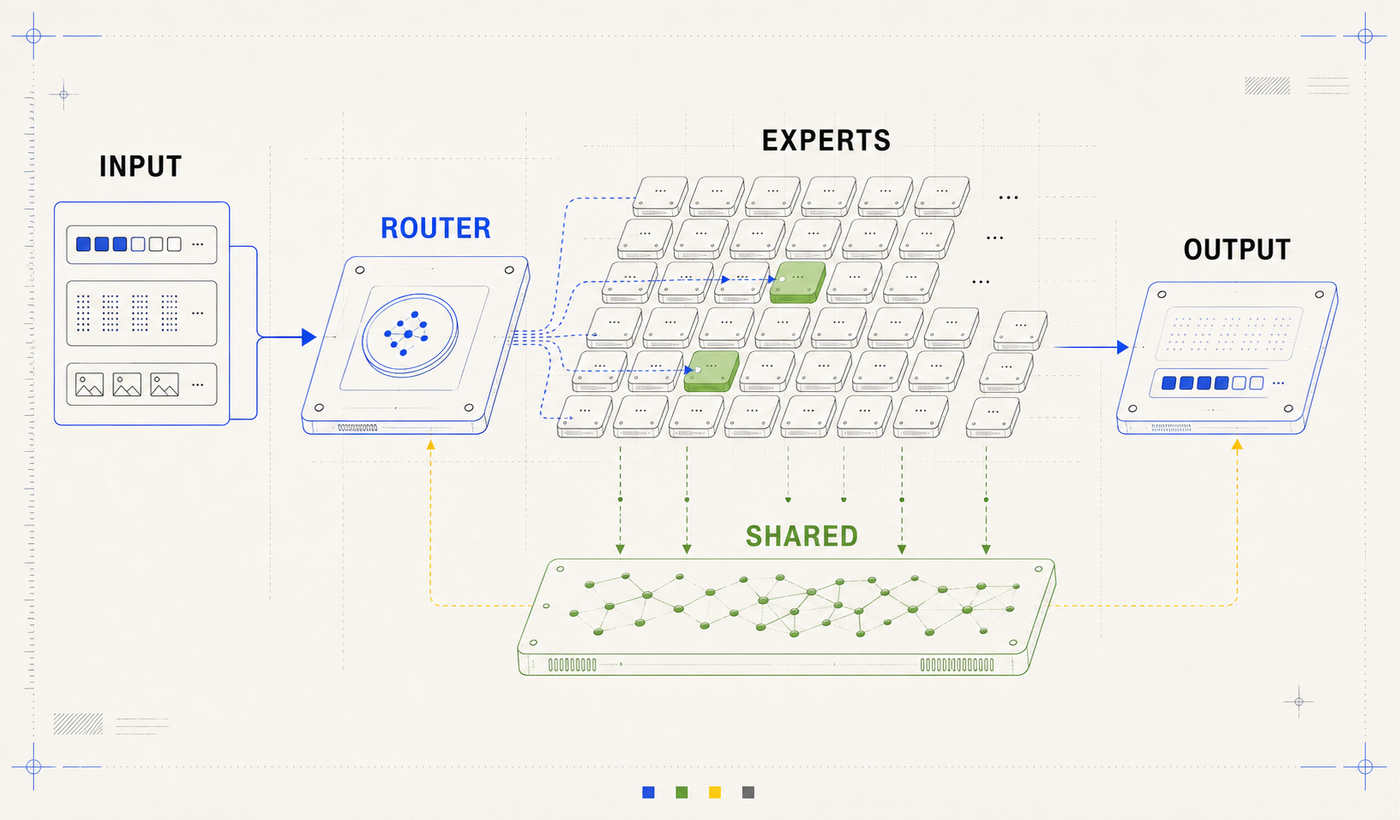
The 26B A4B model keeps many experts available, but activates only a small subset for a given token.
This gives the 26B model a useful production personality:
- It has more representational capacity than a tiny dense model.
- It does not activate the whole model on every token.
- It is a better fit for latency-sensitive agent loops than the 31B dense model when absolute quality is not the only constraint.
For agents, this is important. Tool-calling workflows are often bottlenecked by round trips: plan, call tool, read result, revise, call another tool. A model that is slightly below the dense flagship but materially faster can win the product experience.
PLE is why the edge models are not just tiny dense models
The most interesting edge-device idea in Gemma 4 is Per-Layer Embeddings, or PLE.
Standard token embeddings map a token ID to one embedding vector. PLE adds a parallel, lower-dimensional path that gives each decoder layer its own token-specific signal. In the public Transformers configuration, this per-layer input path has a 256-dimensional hidden size and is packed across the decoder layers.
That sounds like it should make memory worse. The key is that PLE behaves like lookup-heavy representational capacity rather than fully active dense compute. Google describes the tables as large but used for quick lookups, and the edge runtime story leans on memory-mapped PLE to reduce always-resident memory pressure on devices.
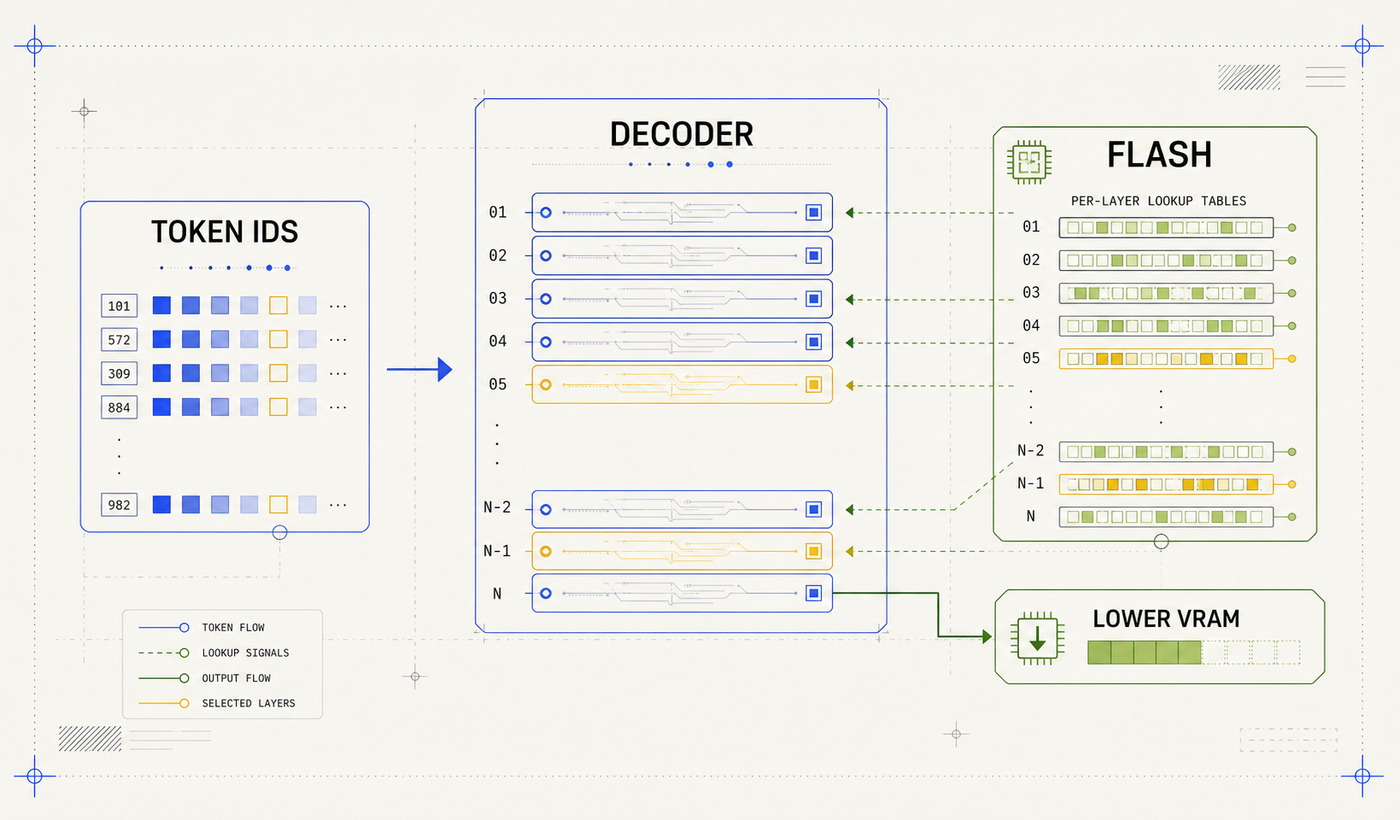
PLE gives each decoder layer a small token-specific signal while reducing the cost of keeping every extra parameter active in memory.
After attention and feed-forward, each decoder layer can receive its own lower-dimensional token signal and fold it back into the hidden state through a lightweight residual path. The total parameter count is larger than the effective active count, but the additional capacity behaves more like storage-backed representational depth than fully active dense compute.
This is the core reason "effective 2B" is a meaningful phrase. It does not mean the model has only 2B total parameters. It means the model is designed so the active inference footprint is closer to the smaller number while representational depth benefits from additional per-layer stored embeddings.
Visual token budgets make multimodality an application knob
Gemma 4 supports text and image input across the family, with audio support on E2B and E4B. The architecture-level detail is what makes this useful for builders:
- The 31B and 26B models use an approximately 550M-parameter vision encoder.
- E2B and E4B use a smaller approximately 150M-parameter vision encoder.
- Images are split into 16 by 16 pixel patches.
- Patches are projected into patch embeddings with learned 2D positions and vision-specific RoPE.
- Groups of 3 by 3 patches are pooled into a single soft token.
- Developers can choose visual token budgets of 70, 140, 280, 560, or 1,120.
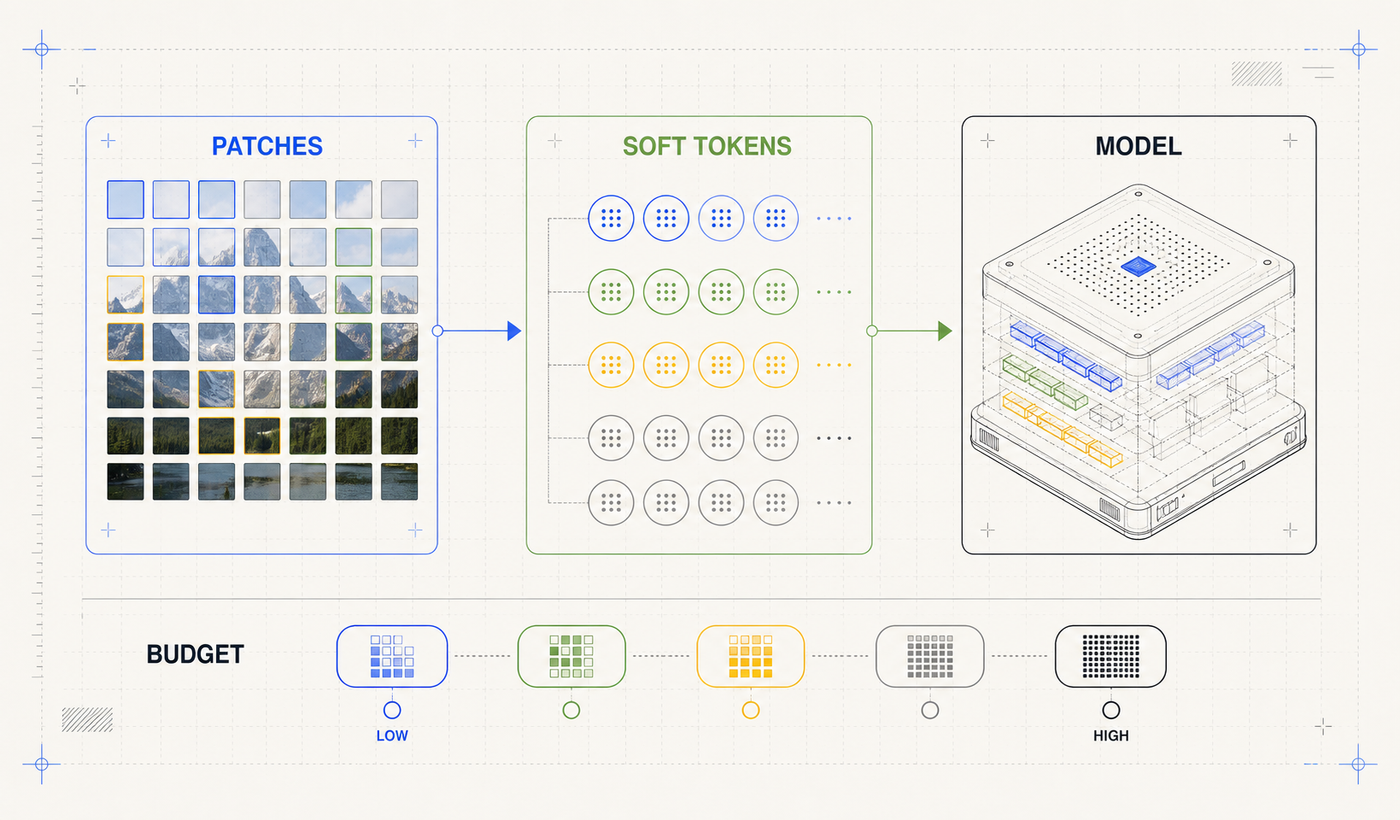
Gemma 4 lets developers trade visual detail for speed by selecting the image token budget.
This turns image processing into an application knob:
| Task | Practical image budget choice |
|---|---|
| Captioning or coarse classification | Lower token budget for throughput |
| Video frame analysis | Lower token budget to process more frames |
| OCR, document parsing, charts, UI screenshots | Higher token budget for small text and spatial detail |
| Object detection and pointing | Higher token budget when precise localization matters |
The audio path is similarly practical. The official model card lists approximately 300M audio encoder parameters for E2B and E4B. In Transformers, raw 16 kHz audio is converted into MEL spectrogram features, then the Gemma 4 processor maps audio into soft tokens with a default 40 ms per token setting.
The model card adds one production detail worth preserving: audio inputs are currently for E2B and E4B, and audio length is capped at 30 seconds. Video support is handled as frames, with a maximum of 60 seconds assuming one frame per second.
For product teams, this changes the pipeline shape. Some workflows that would otherwise look like separate OCR, ASR, vision, and LLM calls can start as a single Gemma 4 evaluation. A dedicated ASR or OCR model may still win for specialized workloads, but the baseline architecture is less glued together than the old "bolt a tool in front of a text model" pattern.
Why this matters for agent workflows
Agent systems need:
- Long context for repositories, documents, traces, and tool output.
- Function calling and structured output for tool loops.
- Multimodal input for screenshots, PDFs, diagrams, audio, and video frames.
- Local deployment when prompts cannot leave the device or tenant boundary.
- Small enough models for always-on assistants and offline interfaces.
- Fast enough models for multi-step loops where latency compounds.
Gemma 4 directly targets that list. The launch blog calls out native function calling, structured JSON output, system instructions, code generation, longer context, and multimodal input. The model card lists thinking mode, function calling, coding, image understanding, video understanding, and multilingual support for 35+ languages after pre-training across 140+ languages.
That native support matters because agent systems are already fragile enough. If function calling, structured output, and system instructions are part of the model behavior, the application does not have to rely as heavily on a prompt template hoping the model emits the right JSON shape.
The cloud and runtime story matters too. Google lists AI Studio and Vertex AI for hosted 31B and 26B prototyping, while model weights are available through Hugging Face, Kaggle, and Ollama. Hugging Face documents day-one support across Transformers, llama.cpp, MLX, WebGPU, Rust, fine-tuning workflows, and local agent integrations (Hugging Face Gemma 4 blog). Google's edge post adds AI Edge Gallery and LiteRT-LM, including on-device Agent Skills experiments powered by Gemma 4 (Google Developers Blog).
For teams that want serverless serving instead of local inference, Google Cloud says Gemma 4 can run on Cloud Run with NVIDIA RTX PRO 6000 Blackwell GPUs and 96GB of vGPU memory, including the 31B instruction-tuned model (Google Cloud Blog).
The license is part of the architecture story. Apache 2.0 makes the family more usable for commercial application teams than the earlier Gemma license posture. It does not mean the training data is open, and it does not remove the need for safety evaluation, but it materially lowers adoption friction.
What still needs evaluation
Open weights and strong benchmarks do not make a model safe for your product by default. The Gemma 4 model card discusses factuality limits, misuse risk, bias, privacy, and the need for application-specific safeguards.
Do not skip evals
Before choosing a Gemma 4 model for an agent workflow, test the full product loop: prompts, tool calls, latency, multimodal inputs, safety boundaries, and failure recovery.
At minimum, evaluate:
- Tool-call JSON validity across realistic prompts.
- Latency across full multi-step runs, not one completion.
- Context degradation when repository, trace, or document inputs get large.
- Multimodal accuracy on your actual screenshots, PDFs, charts, camera frames, or audio clips.
- Safety behavior for the product-specific failure modes you care about.
The point is not that Gemma 4 removes the need for evaluation. It gives teams more places to run the model, more control over deployment, and more architecture choices to match to the workload.
The real lesson
Gemma 4's technical story is not a single breakthrough. It is a set of targeted compromises:
- Local attention for efficiency, global attention for sequence-wide awareness.
- Hybrid attention, p-RoPE, and shared KV-cache choices to keep long context affordable.
- MoE to trade total capacity for lower active compute.
- PLE to put representational depth where edge runtimes can manage it.
- Variable visual token budgets to stop treating every image as equally expensive.
- Apache 2.0 and broad runtime support to make the release operationally useful.
That is why the release is interesting for AI engineers. It is not just a leaderboard entry. It is a model family that exposes the deployment tradeoffs directly.
For edge agents, the answer starts with E2B and E4B. For local-first coding and tool loops, it starts with 26B A4B. For highest-quality open-model experiments, it starts with 31B dense.
The best Gemma 4 model is not the largest one. It is the one whose architecture matches the job.
References
- Gemma 4: Byte for byte, the most capable open models - Google
- Gemma 4 model card - Google AI for Developers
- Bring state-of-the-art agentic skills to the edge with Gemma 4 - Google Developers Blog
- Welcome Gemma 4: Frontier multimodal intelligence on device - Hugging Face
- Gemma4 model documentation - Hugging Face Transformers
- Introducing Gemma 4 on Google Cloud - Google Cloud Blog
- Gemma 3 Technical Report - arXiv:2503.19786
- Gemma 2: Improving Open Language Models at a Practical Size - arXiv:2408.00118
- Gemma: Open Models Based on Gemini Research and Technology - arXiv:2403.08295