
Context Graphs Are the Trillion-Dollar AI Opportunity
- Published on
- Authors

- Name
- Arthur Reimus
- @artreimus
Key Takeaways
- The valuable AI data layer is not only customer, employee, or transaction data. It is the trace of why decisions happened.
- Context graphs make agent memory queryable by connecting entities, policies, approvals, exceptions, tools, and outcomes over time.
- The hard part is not drawing a graph. It is deciding which traces deserve to become durable precedent.
Enterprise AI's biggest opportunity is not chat over every database. It is a system of record for why work happened, not just which row changed.
That is the context graph thesis. Agents sit in the execution path across revenue, support, legal, and security. If they persist the decisions and outcomes they touch, they build a record most companies lack.
Foundation Capital frames this as AI's trillion-dollar opportunity: platforms can capture traces that make existing records actionable (Foundation Capital).
What is a context graph?
A context graph is a knowledge graph for decision traces stitched across entities and time (Foundation Capital). Neo4j describes graphs as data modeled with nodes, relationships, and properties (Neo4j graph database concepts). Here, nodes are accounts, policies, tickets, contracts, documents, approvals, and agent runs.
Relationships say which evidence supported an action, who approved an exception, which policy version applied, and what changed afterward.
That differs from ordinary enterprise data modeling. A customer graph says customer A owns contract B. A context graph says agent run C used contract B, compared policy D, routed exception E, and wrote state G back to the CRM.
Edge labels such as USED, APPROVED, OVERRIDES, and LATER_RESULTED_IN turn scattered traces into queryable memory. You can traverse from a decision to evidence, or from a bad outcome to similar approvals.
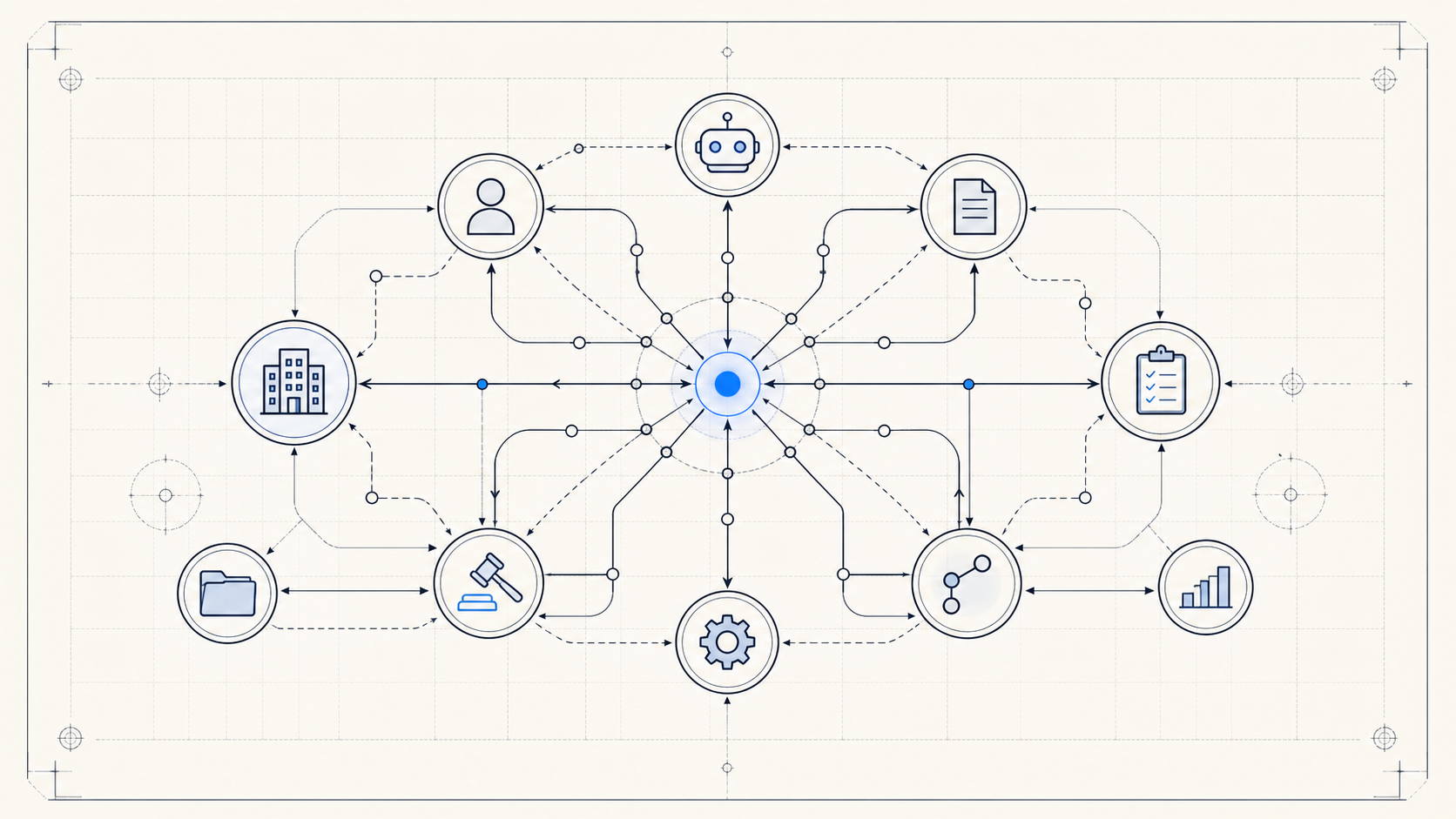
A context graph connects entities, approvals, evidence, tools, and outcomes into a traceable path.
What context graphs record that CRMs cannot
A CRM knows the account. Tickets know the escalation. Billing knows the invoice.
It should answer questions like:
- Which policy version applied when we approved this discount?
- Who granted the exception, and what precedent did they cite?
- Which source or tool result changed the agent's recommendation?
- Did the same decision pattern later produce churn, fraud, or delay?
Those are path questions. The answer lives in relationships.
Account -> HAS_CONTRACT -> Contract is useful. AgentRun -> RECOMMENDED_EXCEPTION -> Approval -> OVERRIDES_POLICY -> PolicyVersion is where autonomy starts to become auditable.
Why agents create the graph better than humans do
Humans are bad at writing down context. We summarize after the fact and forget which evidence changed the decision.
Agents are different because much of the trace is already in the runtime: retrieved documents, tool calls, policy checks, approvals, and final writes. Later outcomes can be linked back as feedback. Capturing that is engineering work, not clerical work for the operator.
This is why glue functions are the wedge. RevOps, SecOps, legal ops, deal desk, compliance review, and customer escalation teams exist because no single application owns the real workflow. They bridge systems and carry exceptions.
An agent that helps with that workflow should leave behind a structured trace the next agent can query.
The implementation shape is becoming concrete
Neo4j's Create Context Graph project scaffolds a Neo4j-backed FastAPI and Next.js app with streaming chat, graph visualization, domain ontology, Cypher tools, and demo data from one uvx create-context-graph command (Neo4j Create Context Graph). The pattern is practical: import systems, synthesize traces, then let agents query the graph.
Cognee takes a similar memory-layer view. Its docs describe .remember, .recall, .improve, and .forget: ingest data, extract relationships, query memory, enrich it, and delete it when needed (Cognee introduction).
Neo4j's AI systems page gives the enterprise version: use knowledge graphs to ground agents, manage context, explain actions, and support long-term agent memory (Neo4j AI Systems).
The architecture is straightforward: ingest objects, extract events, store relationships with time and provenance, retrieve subgraphs, and feed outcomes back into the graph.
The product opportunity is not the database. It is the workflow deciding what becomes memory.
Context graphs are not just better RAG
It is tempting to call this GraphRAG and move on. That misses the economic point.
RAG answers a question using external context. A context graph changes what the company knows after the question is answered.
If a support agent looks up a policy and replies to a customer, ordinary RAG might cite the policy. A context graph should also record the plan, contract version, policy version, denial reason, approver, and outcome.
That record becomes useful in three ways: retrieval gets sharper, audits become paths through evidence instead of theater, and every workflow leaves precedent. Over time, the graph becomes a map of how the company actually operates.
The hard part is deciding what deserves to persist
The failure mode is obvious: teams dump every prompt, tool result, chat message, and output into a graph and call it memory.
That is just expensive logging with edges.
A useful context graph needs sharper contracts: identity resolution, temporal modeling, retrieval-time permissions, trace hygiene that stores user-visible rationale instead of raw hidden model chain-of-thought, and lifecycle rules so bad precedent can expire.
This is where most "memory for agents" demos get too cute. The demo remembers facts. The production system remembers ownership, provenance, and lifecycle too.
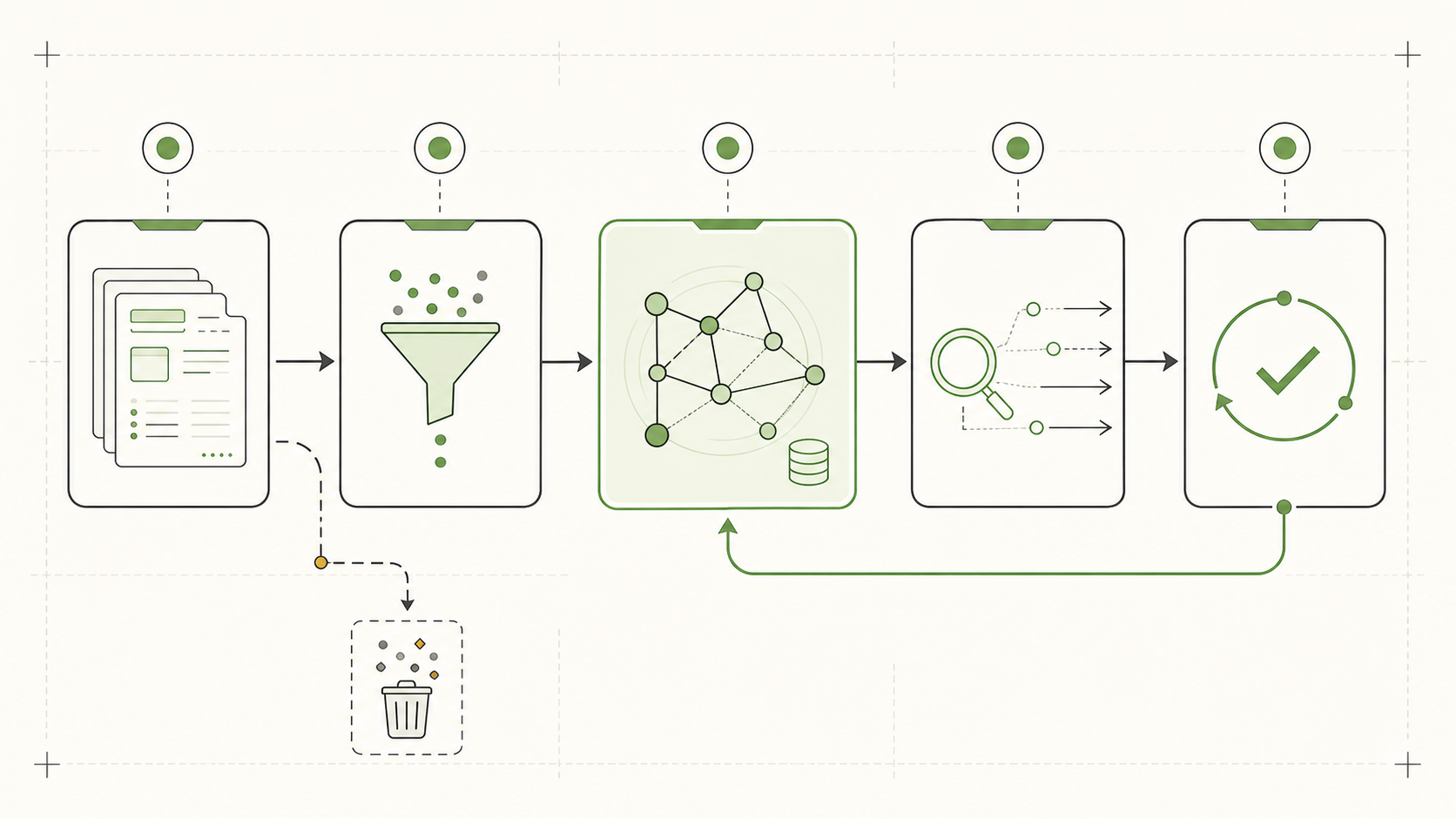
Useful memory is filtered from traces, retrieved deliberately, and corrected by later outcomes.
The trillion-dollar question is distribution
The primitive is clear enough: graph-shaped memory for agentic workflows. The market question is who gets to own it.
Incumbent systems of record already own the nouns: accounts, employees, tickets, contracts, invoices. Agent startups may own the verbs: investigate, approve, reconcile, remediate, negotiate, renew, escalate.
The context graph forms where the verbs cross the nouns.
That makes the best wedge less likely to be "a general memory layer for all agents" and more likely to be a workflow where decisions are frequent, cross-system, regulated, and expensive to get wrong: deal desk, claims, KYC, incident response, procurement exceptions, customer escalations.
Start narrow. Capture the trace. Make precedent queryable. Prove that future decisions get faster or more defensible.
If that works, the graph becomes more than context for the model. It becomes context for the company.