
Production Agents Need Context Engineering, Not Just Bigger Models
- Published on
- Authors

- Name
- Arthur Reimus
- @artreimus
Key Takeaways
- Production agents become expensive and brittle when every loop drags stale context forward.
- Context engineering decides what belongs in the active prompt, cache, tool memory, code execution, and compacted state.
- GitHub Copilot's caching story shows why small context-efficiency gains can matter at production scale.
Production agents do not fail like demos fail. A demo fails when the model chooses the wrong tool or gives a bad answer. A production agent fails more quietly: each loop gets more expensive, the first token arrives later, tool results pile up, and the model starts reasoning over leftovers.
Past a certain scale, reliability is not just a model problem. It is a context problem.
Brad Abrams' Code w/ Claude 2026 session, "Getting more out of the Claude Platform", made that operational side concrete. The pattern is simple: cache what repeats, retrieve what is needed, filter what comes back, compact what gets old, and ask a stronger model only when the decision deserves it.
Context engineering is the discipline behind that pattern. It decides what deserves to be in the model's active context, what should be retrieved just in time, what should be summarized, and what should stay outside the prompt entirely.
The production pattern: cache, search, execute, compact, advise. Cache the stable prefix, search the tool catalog, execute against bulky data outside the prompt, compact old turns into durable task state, and call an advisor model when the decision deserves stronger reasoning.
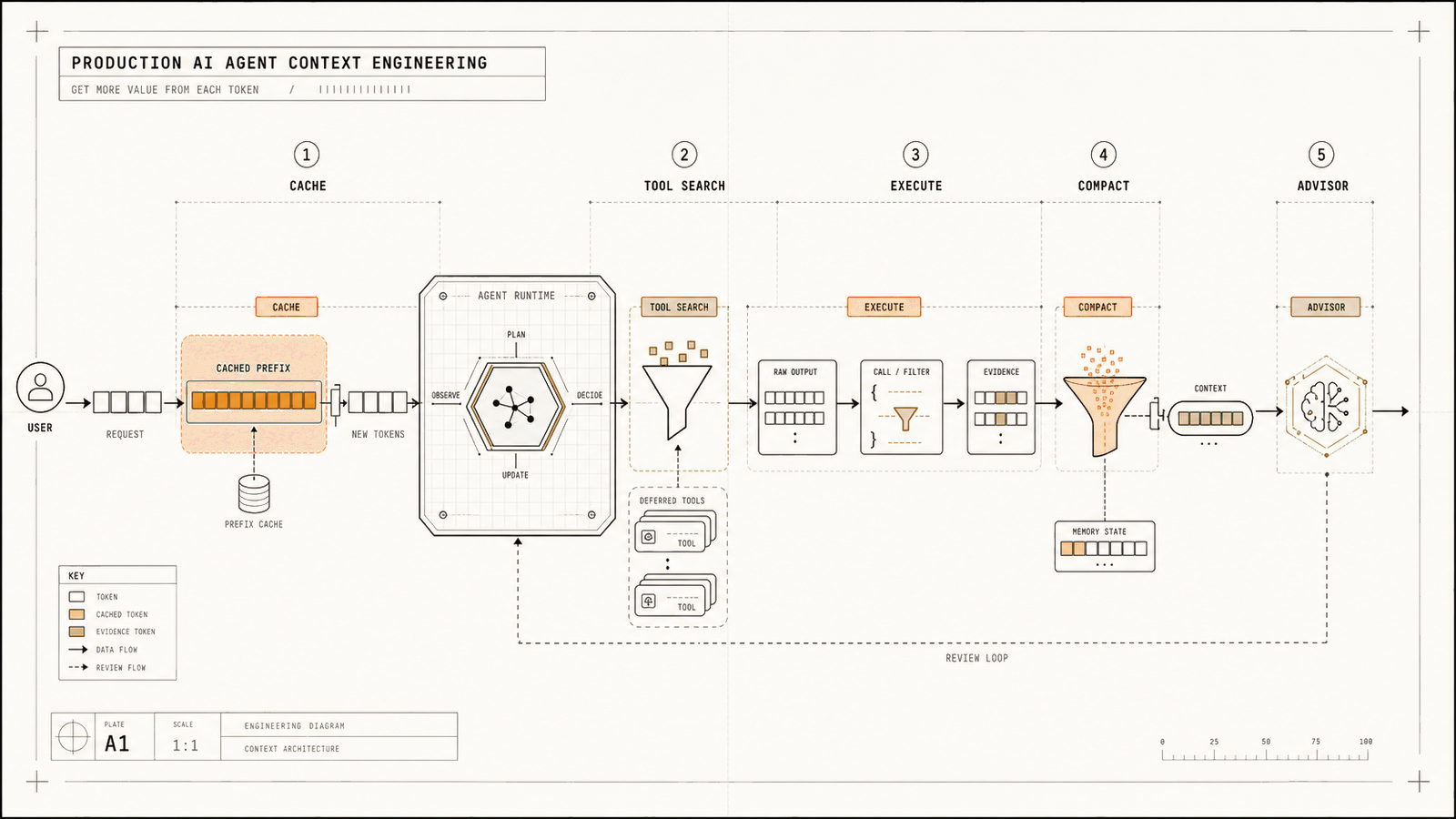
A production agent should treat context as a managed resource. Each step decides what enters the active model context and what stays in cache, tool memory, code execution, or compacted state.
It is not one feature. It is a stack of pressure valves: prompt caching for repeated prefixes, tool search for oversized catalogs, programmatic tool calling for oversized results, compaction for long histories, and advisor calls for cases where better reasoning is worth paying for.
Prompt caching is the first production tax break
Long-running agents repeat stable context constantly: tool schemas, system instructions, examples, policies, and earlier turns that did not change.
Prompt caching turns that repeated prefix into a cost lever. Anthropic describes it as resuming from specific prompt prefixes to reduce processing time and cost, with cache reads priced at 0.1x the base input-token price for supported models (Anthropic prompt caching docs).
Because cache keys follow prefix order, tools, then system, then messages, stable tool definitions, system instructions, examples, policies, and long-lived context belong before the cache breakpoint. Request-specific user input and retrieved state go after it.
Dynamic content before the cache point creates misses.
GitHub Copilot is the scale case. In Anthropic's GitHub Copilot case study, the team described why caching is not polish at that volume: a 1% caching gain can mean millions in savings, cached input is 10% of normal input cost, Copilot targets 94%-96% hit rates, and a drop toward 70% usually means a bug or bad prompt assembly. Their rules are concrete: keep prefixes stable, keep UUIDs out of system prompts, regression-test tool catalogs because dynamic tool loading can invalidate the conversation cache, and preserve cache affinity when a harness switches models.
Tool definitions are not free
Most agent teams underestimate tool definitions because they do not look like user data. They are schemas and descriptions, "just metadata."
Then the agent has 80 tools, 200 tools, or a full MCP-powered workspace where every service brings its own catalog. The model has to read that catalog before it works.
Anthropic's tool search docs describe the scaling problem directly: multi-server setups can spend large chunks of context on tool definitions before the task begins, and tool selection degrades once the tool count gets too high. The documented solution is deferred loading: provide a search tool plus a catalog where most tools are marked with defer_loading: true; Claude searches tool metadata, then only the relevant references are expanded into full definitions (Anthropic tool search docs).
That gives you a cleaner invariant:
The model should know how to find tools before it knows every tool.
For small agents, this is unnecessary ceremony. If you have five tools and all five are used on nearly every request, load them. For enterprise agents, attention is the product surface.
Tool results should not become prompt landfill
Tool search handles the front door: which tool definitions enter the prompt. Programmatic tool calling handles the back door: what happens after tools return too much data.
The usual failure mode is easy to reproduce. A tool returns a giant JSON payload, an HTML page, a CRM export, a meeting transcript, or all rows that might be relevant. The orchestration layer stuffs the whole result into the next model call.
Programmatic tool calling changes that contract. Anthropic describes it as letting Claude write code inside a code execution container to call tools, aggregate results, filter data, and return only the relevant output to model context (Anthropic programmatic tool calling docs).
In production, the model should reason over evidence, not raw exhaust. Load only relevant tool definitions, let code filter bulky tool results, and compact stale turns into task state.
Compaction preserves state, not nostalgia
Eventually, even careful agents run long. They plan, call tools, revise the plan, hit errors, recover, test, and continue.
Compaction is the blunt tool for that moment. Anthropic describes server-side compaction as summarizing older context when a long-running conversation approaches a configured token threshold. The API creates a compaction block, continues from the summary, and later requests can drop message blocks before that point (Anthropic compaction docs).
Server-side compaction is still a gated feature: Anthropic lists it as beta and requires the compact-2026-01-12 beta header.
Good compaction preserves the task goal, decisions, open questions, evidence, changed files or records, active constraints, and next actions. Bad compaction preserves vibes.
If the summary cannot tell the next model call what must remain true, it is amnesia with nicer formatting.
Advisor models are senior review on demand
The same context discipline applies to model routing. Using the most expensive model for every step is wasteful, but naive routing is worse.
Anthropic's advisor docs describe pairing a faster executor model with a higher-intelligence advisor model that can provide strategic guidance mid-generation (Anthropic advisor tool docs). It is a beta feature, so this is not a "flip it on everywhere" recommendation.
Bad model routing is invisible roulette: send some requests to cheap models, some to expensive models, hope the product feels consistent. The advisor pattern is more explicit: the executor owns the flow, and the advisor is called for high-impact, low-confidence, or expensive-to-miss decisions.
In the Hero Corp AI demo, the advisor catches a buried renewal requirement the executor missed. That is the useful version of the pattern.
Conclusion
Production agents do not get reliable just because the model gets bigger. They get reliable when the runtime controls what the model sees.
Cache the stable prefix so repeated instructions and tool schemas stop dominating cost. Search large tool catalogs instead of loading every definition. Use programmatic tool calling to turn bulky results into evidence. Compact old turns into durable task state. Call an advisor model only when better judgment changes the outcome.
That is the real lesson: context is not background material. It is the operating surface for cost, latency, reliability, and reasoning quality.
References
- Anthropic, "Getting more out of the Claude Platform", Code w/ Claude 2026 San Francisco, May 6, 2026.
- Anthropic, "Caching, harnesses, and advisors: Building on Claude at GitHub scale", Code w/ Claude 2026 San Francisco.
- Anthropic, "Prompt caching".
- Anthropic, "Tool search tool".
- Anthropic, "Programmatic tool calling".
- Anthropic, "Compaction".
- Anthropic, "Advisor tool".
- GitHub Docs, "Hosting of models for GitHub Copilot".
- GitHub Docs, "Models and pricing for GitHub Copilot".