Imagine a system that not only "thinks" through problems but also takes real-world actions to verify its ideas—a model that interleaves internal reasoning with external tool use to navigate complex tasks. This is the promise of the ReAct (Reasoning and Action) agent model. In this post, we'll unpack what ReAct is, how it integrates reasoning and acting, and where it stands in today's rapidly evolving landscape of large language model (LLM) applications. Drawing on recent research (Yao et al., 2022), we'll dive into its inner workings, core components, benefits, and practical trade-offs.
1. React, Act, and ReAct
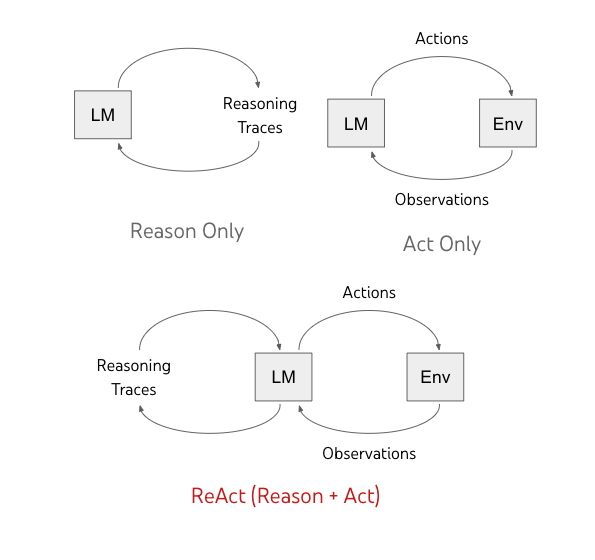
Figure 1: Different approaches to language model interaction: Reason Only (left) uses self-contained reasoning traces, Act Only (right) focuses on environment interaction, while ReAct (bottom) combines both for enhanced problem-solving.
In the landscape of LLM prompting strategies, three distinct approaches have emerged:
Act-Only Prompting focuses on direct action generation without explicit reasoning steps. Models are prompted to interact with tools or environments immediately based on the input. While efficient for straightforward tasks, this approach can struggle with complex scenarios that require careful deliberation or multi-step planning.
Chain-of-Thought (CoT) Reasoning enables models to generate detailed, step-by-step explanations of their thinking process. This approach improves problem-solving capabilities but remains isolated from external sources, limiting the model to its training data.
ReAct changes the game by combining the strengths of both approaches. It interleaves internal reasoning with concrete actions—allowing the model to not only explain its thought process but also to interact with the external environment to fetch real-time data, verify facts, or complete tasks.
Research has shown that ReAct significantly outperforms both Act-Only and Chain-of-Thought approaches across various tasks. In question-answering benchmarks, ReAct achieved up to 30% higher accuracy compared to Act-Only methods and showed more reliable fact verification than pure reasoning approaches. The synergy between reasoning and acting enhances both interpretability and reliability, enabling more dynamic and human-like problem-solving processes.
ReAct augments the action space of an LLM by enabling it to produce both free-form reasoning traces and actionable steps. This synergy enhances interpretability and allows the model to leverage external tools, resulting in a more dynamic and human-like problem-solving process.
2. How Does ReAct Work?
At its core, the ReAct operates by alternating between generating internal reasoning ("thoughts") and executing actions. Let's break down the process:
Internal Reasoning: The model generates natural language descriptions that decompose the task, plan subsequent steps, and correct its course if necessary.
Action: Based on its reasoning, the model executes task-specific actions—such as calling a search API, looking up a fact, or interacting with a web interface. The outcome of these actions (observations) feeds back into the model, refining further reasoning and actions.
Observation: Every observation is added to the context, ensuring that subsequent decisions are grounded in both the model's internal logic and real-world data.
Example Scenario from HotpotQA

Figure 2: ReAct example scenario from HotpotQA: Seven Brief Lessons on Physics
To illustrate how ReAct works in practice, let's analyze how it solves this question: "Seven Brief Lessons on Physics was written by an Italian physicist that has worked in France since what year?"
The agent starts with a thought to decompose the task: "I need to search Seven Brief Lessons on Physics, find its author, then find when he has worked in France."
This leads to an action: Search[Seven Brief Lessons on Physics]
The observation reveals: "Seven Brief Lessons on Physics (Italian: Sette brevi lezioni di fisica) is a short book by the Italian physicist Carlo Rovelli. Originally published in Italian in..."
A new thought processes this information: "The author of Seven Brief Lessons on Physics is Carlo Rovelli. I need to search Carlo Rovelli next and find when he has worked in France since."
Another action: Search[Carlo Rovelli]
The observation provides: "Carlo Rovelli is an Italian theoretical physicist and writer who has worked in Italy, the United States and, since 2000, in France. He is also currently a Distinguished Visiting Research Chair at the Perimeter Institute..."
Final thought: "Carlo Rovelli has worked in France since 2000, so the answer is 2000."
This example demonstrates how ReAct:
- Breaks down the problem into logical steps
- Uses search actions to gather information
- Processes observations to inform next steps
- Arrives at the correct answer through a series of thought-action-observation cycles
3. Key Components of ReAct
The ReAct framework is built upon several core components that work in concert to integrate reasoning and action:
- Large Language Model (LLM): The heart of the system, capable of generating both reasoning traces and actions. Any capable LLM (such as GPT-4) can serve this role.
- External Tools: These are APIs or utilities (e.g., search engines, math tools) that the model can call upon to retrieve real-time information or perform specific tasks.
- Chain-of-Thought (CoT) Prompting: This component supports the generation of detailed reasoning traces that break down complex tasks into sub-steps, providing a scaffold for subsequent actions.
- ReAct Prompting: A specialized prompting strategy that directs the model to produce an interleaved sequence of thoughts and actions, enabling dynamic adaptation as new observations are made.
4. Pros and Cons of the ReAct
ReAct agents, which integrate reasoning and action in large language models, offer several advantages and disadvantages:
Pros:
Enhanced Problem-Solving:
By combining reasoning with action, ReAct agents can approach problems more like humans—breaking down complex tasks into manageable steps and making informed decisions.Integration with External Tools:
These agents can interact with search engines, databases, APIs, or other external resources, allowing them to access real-time information and perform tasks beyond their initial training data.Adaptive Learning:
ReAct agents learn from their actions and observations, adjusting their strategies in real time to handle unforeseen challenges and improve effectiveness over time.Transparency and Interpretability:
The explicit reasoning traces generated by ReAct agents provide insight into their decision-making processes, which enhances user trust and facilitates debugging.
Cons:
Increased Computational Resources:
The iterative process of reasoning and acting can lead to higher computational costs and longer processing times, especially when handling simple tasks.Token Limitations:
Continuous reasoning and action steps can cause the token count to accumulate rapidly, potentially leading to issues with language model token limits.Error Propagation:
If an early reasoning step is flawed, subsequent actions based on that step may also be incorrect, potentially compounding errors throughout the process.Dependence on External Tools:
The effectiveness of ReAct agents is partly dependent on the integration of external tools. If these tools are unavailable or improperly integrated, the overall performance of the system could suffer.
5. A Guide to ReAct Prompting
Implementing ReAct effectively requires careful attention to prompt engineering and error handling. This section provides practical guidelines and examples to help you structure your ReAct prompts for optimal performance. We'll explore common patterns, best practices, and key implementation considerations that will help you build more robust ReAct-based systems.
Common ReAct Implementation Patterns
- Start Simple
- Begin with basic thought-action loops
- Example: Search → Think → Act pattern
- Add Progressive Complexity
- Layer in error handling
- Implement feedback loops
- Add more external tools
- Best Practices
- Keep thoughts focused and actionable
- Maintain clear state tracking
- Handle edge cases explicitly
Prompting Format
The standard ReAct prompting template, as demonstrated by Harrison Chase (Co-Founder and CEO at LangChain) in the LangChain Hub, follows a structured sequence:
Answer the following questions as best you can. You have access to the following tools:
{tools}
Use the following format:
Question: the input question you must answer
Thought: you should always think about what to do
Action: the action to take, should be one of [{tool_names}]
Action Input: the input to the action
Observation: the result of the action
... (this Thought/Action/Action Input/Observation can repeat N times)
Thought: I now know the final answer
Final Answer: the final answer to the original input question
Begin!
Question: {input}
Thought:{agent_scratchpad}
Example Input and Output
Input:
Question: What is the elevation range for the area that the eastern sector of the Colorado orogeny extends into?
Output:
Thought: I need to search "Colorado orogeny" and find the area that the eastern sector extends into.
Action: Search[Colorado orogeny]
Observation: The Colorado orogeny was an episode of mountain building in Colorado and surrounding areas.
Thought: It does not mention the eastern sector. I need to look up "eastern sector".
Action: Lookup[eastern sector]
Observation: The eastern sector extends into the High Plains.
Thought: The High Plains' elevation range needs to be found.
Action: Search[High Plains]
Observation: The High Plains rise from around 1,800 to 7,000 ft.
Final Answer: 1,800 to 7,000 ft.
Key Implementation Tips
When implementing ReAct in your applications, consider these essential practices that can significantly improve the reliability and effectiveness of your system:
Error Recovery Implement robust error handling to gracefully manage failed actions and maintain system stability.
# Bad: Continuing without addressing errors Thought: Search failed. Let me try the next step. # Good: Explicit error handling Thought: Search failed. Let me try an alternative search term Action: Search[alternative term]State Management Maintain clear context throughout the reasoning chain to ensure coherent decision-making.
# Bad: Losing context Thought: I found some information # Good: Clear context tracking Thought: I found that X costs $50. Given the budget of $100, I can proceed.Action Planning Structure actions deliberately with clear goals and fallback strategies.
# Bad: Random actions Action: Click random buttons # Good: Structured exploration Thought: I need to find X. I'll check the menu first, then search if needed. Action: Check menu
6. Conclusion
The ReAct framework represents a significant leap forward in how we approach AI problem-solving by introducing a powerful three-part cycle: reasoning, acting, and observing. While traditional approaches forced us to choose between models that think deeply (like chain-of-thought) or act quickly (like task-specific agents), ReAct demonstrates how these capabilities can work together synergistically.
The power of ReAct lies in how these three components reinforce each other:
Reasoning: The model breaks down problems and plans next steps through explicit thought processes. This isn't just internal monologue - it's strategic planning that guides concrete actions.
Acting: Instead of getting stuck in analysis paralysis, the model takes decisive actions based on its reasoning - whether that's searching for information, making calculations, or interacting with external tools.
Observing: Each action produces real-world feedback that the model can learn from. These observations feed back into the reasoning process, creating a dynamic loop of continuous improvement.
The results speak for themselves - ReAct achieves up to 30% higher accuracy than traditional approaches on complex tasks like multi-hop question answering. While the system requires more computational resources due to its iterative nature, the trade-off brings substantial benefits: improved reliability, better error handling, and most importantly, the ability to adapt strategies based on real-world feedback.
For the future of AI systems, ReAct points to a crucial insight: effective AI isn't just about having powerful models - it's about creating systems that can think carefully, act decisively, and learn continuously from their interactions with the world. This combination of capabilities will be essential as we work to build AI systems that we can trust with increasingly complex and consequential tasks.
For developers and researchers looking to implement ReAct, start small. Begin with simple thought-action loops in controlled environments, then gradually increase complexity as you understand the system's behavior. Pay particular attention to error handling and state management - these are often the difference between a robust ReAct system and one that fails in production.
The future of AI isn't just about models that can think or models that can act - it's about systems that can do both, thoughtfully and reliably. ReAct shows us a practical path toward that future.
References
- ReAct: Synergizing Reasoning and Acting in Language Models (Yao et al., 2022)
- ReAct Prompting Guide (Prompting Engineering Institute)
- ReAct-LangChain Prompt Template (LangChain Hub)
- ReAct: Combining Reasoning and Action (Google Research Blog)
Image Attribution
The River Severn at Shrewsbury, Shropshire, 1770 by Paul Sandby